在这里记录一些我觉得比较好的面试题
1. 给你10g的字符串数据,内存只有256mb,如何实现排序
1.1 多路并归
首先将10G的数据分为10 * 1024 / 256 = 40块分别读入后进行排序。
之后采用多路归并的方法实现排序:
将每一个小文件的第一个数取出,即每一个小文件里的最小数,对这些数进行归并排序,将这些数里的最小数字num(i)写入大文件的第一行,然后将对应文件的指针加一并读入新的值,同时大文件的指针加一,重复该操作直到全部写入完毕。
假设数据被分为了k段,总共的数据量为n,我们每次获取最小值需要遍历k次,一共需要比较n次,每块数据排序耗时log(n / k),总共的时间复杂度为O(k*log(n/k) + nk)
1.2 败者树
败者树,图解败者树,算法执行调整每一步详细分析 - 正在加载…… - 博客园 (cnblogs.com)
败者树同样也要先排序,但是每次寻找最小值的世界复杂度为O(log(k))左右,总时间复杂度大致为O(k*log(n/k) + n * log(k))
2. 写一个java方法,实现参数a,b值的交换
这个题目一上来就挺懵逼的,因为Java是值传递,所以基本数据类型咱就别想了,如果是包装类,则可以通过反射进行交换:
public static void swap(Integer a, Integer b) throws Exception {
Integer temp = new Integer(a);
Field field = Integer.class.getDeclaredField("value");
field.setAccessible(true);
field.set(a, b);
field.set(b, temp);
}
java
但是这样有风险,咱们都知道包装类在[-128, 127]以内的数字返回的都是同一个对象,也就是说我们要是修改了这些值,也会影响后续的对象:
Integer a = 1, b = 2;
swap(a, b);
System.out.println(a);
System.out.println(b);
Integer test = 1;
System.out.println(test);
java
输出:
2 1 2text
具体内容可以看Integer#valueOf
在测试的时候发现一个有趣的现象:
Integer a = 1, b = 2;
swap(a, b);
System.out.println(a + " " + b);
java
输出:
Exception in thread "main" java.lang.InternalError: Storage is not completely initialized, 1 bytes left at java.base/java.lang.StringConcatHelper.newString(StringConcatHelper.java:346) at juc.CHMTest.main(CHMTest.java:13)text
用debug稍微看了一下,不知道为什么。。
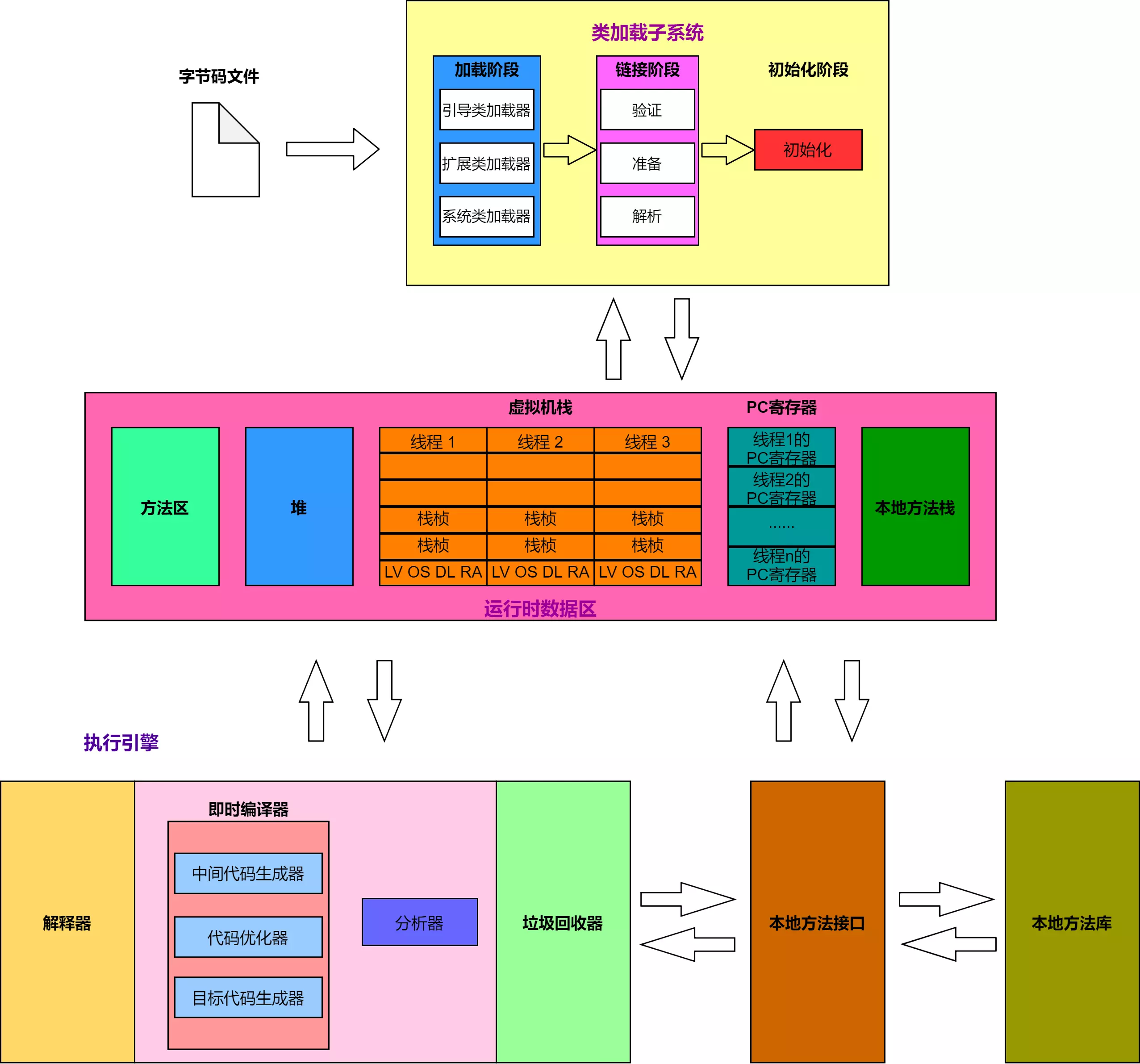
3. JVM有哪些部分
这种东西一定要记一共有几个,不然容易说漏。
JVM从整体分为三部分:类加载子系统、运行时数据区以及执行引擎。
运行时数据区包括五部分:方法区、堆、虚拟机栈、PC寄存器以及本地方法栈
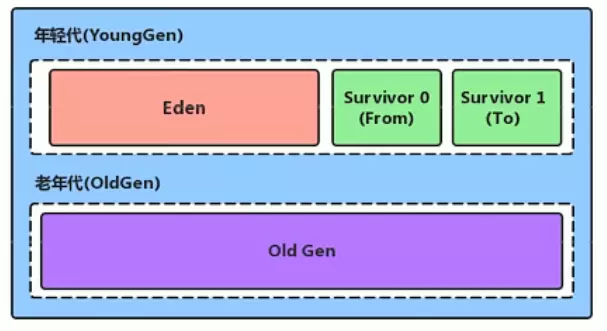
4. 堆在垃圾回收的场景下分哪几部分?每部分如何进行GC?
第一问很简单:总体分为年轻代和老年代,默认占比为1:2。
可以通过-XX:NewRatio可以设置新生代的比例,但是不要字面理解这个配置的意思:
-
默认
-XX:NewRatio=2,代表新生代占1,老年代占2,新生代占整个堆的1/3 -
比如
-XX:NewRatio=4,代表新生代占1,老年代占4,新生代占整个堆的1/5
新生代又分为伊甸园区、幸存者0区和幸存者1区,默认占比为8:1:1,可以通过-XX:SurvivorRatio进行调整。
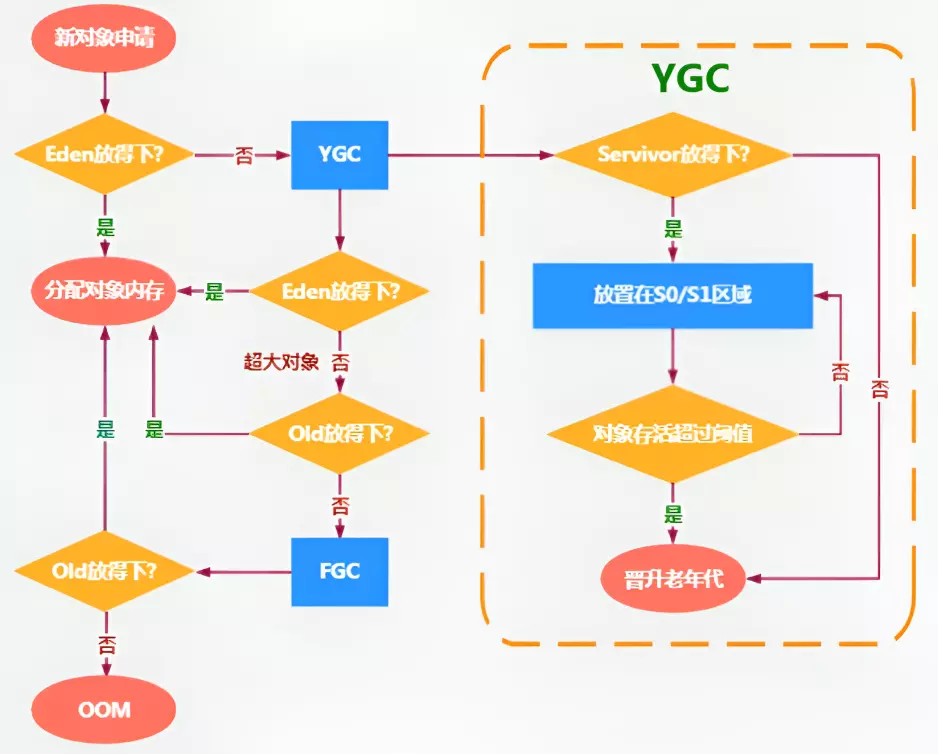
关于第二问,年轻态的GC称为Young GC(下面简称YGC)或者Minor GC,触发条件如下:
- new的对象优先放到伊甸园区
- 当伊甸园区的空间不足时,此时进行YGC,清除Eden区的所有垃圾,并将存活的对象放到幸存者0区
- 如果再次触发垃圾回收,清除Eden区和幸存者0区的垃圾,并将存活的对象放到幸存者1区
- 如果再次重复,清除Eden区和幸存者1区的垃圾,并将存活的对象放到幸存者0区
- ....
特殊情况:
- 当某个对象循环超过指定次数后,会被放到老年代,默认为15次,可以通过
-XX:MaxTenuringThreshold=<N>设置 - 如果在垃圾回收后仍然无法在Eden区给对象分配内存,那么对象会直接升级到老年代,如果老年代空间也不足,并且通过Full GC也不足,则会抛出OOM异常
- 由Eden区、from区向to区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
5. 用过ES吗?请说一下倒排索引
这个东西太长了,建议自行百度了解。
ES之倒排索引详解_es倒排索引_wh柒八九的博客-CSDN博客
6. Spring用了哪些设计模式
[Spring中用到了哪些设计模式? - murphy_gb - 博客园 (cnblogs.com)](https://www.cnblogs.com/kyoner/p/10949246.html#:~:text=Spring 框架中用到了哪些设计模式: 工厂设计模式%3A Spring使用工厂模式通过 BeanFactory、ApplicationContext 创建 bean 对象。,Spring AOP 功能的实现。 单例设计模式%3A Spring 中的 Bean 默认都是单例的。)
7. 简单说一下B+树
一文彻底搞懂MySQL基础:B树和B+树的区别_b树和b+树有什么区别_公众号:码农富哥的博客-CSDN博客
8. 聚集索引和非聚集索引是什么
聚集索引与非聚集索引的总结 - {-)大傻逼 - 博客园 (cnblogs.com)
大致意思就是数据库会根据聚集索引去创建对应的表,而表中实际的数据也存在这里面。非聚集索引只会保存对应的键以及它所指向的主键值,因此使用非聚集索引查询时,会进行两次查询:第一次根据非聚集索引拿到主键值,再根据主键值到聚集索引里去查数据。
聚簇索引:数据文件和索引文件在一起
非聚簇索引:数据文件和索引文件分开
9. MyISAM和InnoDB引擎的区别
MyISAM VS InnoDB - 知乎 (zhihu.com)
MySQL引擎详解(二)——MyISAM引擎特性_永远是少年啊的博客-CSDN博客
| InnoDB | MyISAM | |
|---|---|---|
| 事务支持 | 支持 | 不支持 |
| 表级锁定 | 锁行,前提是用了主键 | 锁整个表 |
| 读写锁 | 在锁行的前提下,读写互不影响 | 只能一个写,或者多个读 |
| 缓存 | 缓存数据+索引 | 只缓存索引 |
| 查询效率(相对) | 一般 | 高 |
| 增删改效率(相对) | 一般 | 低 |
| AUTO_INCREMENT | 自动增长列只能是组合索引的第一列 | 自动增长列可以是组合索引的任意列 |
| 外键 | 支持 | 不支持 |
| 主键 | 必须有 | 可以没有 |
| 表的具体行数 | 会遍历整个表 | 保存了总行数,查询时会直接取出来 |
| 聚簇索引 | 是 | 否 |
10. Spring Bean的生命周期
spring生命周期七个过程_面试官:请你讲解一下Spring Bean的生命周期_weixin_39911567的博客-CSDN博客
11. Spring Bean的作用域
| 作用域 | 描述 |
|---|---|
| singleton | 注册一个单例的bean,这是默认的注册方式 |
| prototype | 每次从容器中调用Bean时,都返回一个新的实例 |
| request | 每次Http请求都会创建一个新的Bean |
| session | 同一个HttpSession都会共享一个Bean |
| application | 限定一个Bean的作用域为ServletContext的生命周期。该作用域仅适用于web的Spring WebApplicationContext环境。 |
12. MySql的四种事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ_UNCOMMITTED(读未提交) | 可能 | 可能 | 可能 |
| READ_COMMITTED(读提交) | 不可能 | 可能 | 可能 |
| REPEATABLE_READ(可重复读) | 不可能 | 不可能 | 可能 |
| SERIALIZABLE(串行化) | 不可能 | 不可能 | 不可能 |
脏读
脏读指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并不一定最终存在的数据,这就是脏读。
可重复读
可重复读指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据都是一致的。通常针对数据**更新(UPDATE)**操作。
不可重复读
对比可重复读,不可重复读指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响,比如其他事务改了这批数据并提交了。通常针对数据**更新(UPDATE)**操作。
幻读
幻读是针对数据**插入(INSERT)**操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现好像刚刚的更改对于某些数据未起作用,但其实是事务B刚插入进来的,让用户感觉很魔幻,感觉出现了幻觉,这就叫幻读。
不可重复读一般针对UPDATE,而幻读重点在INSERT和DELETE