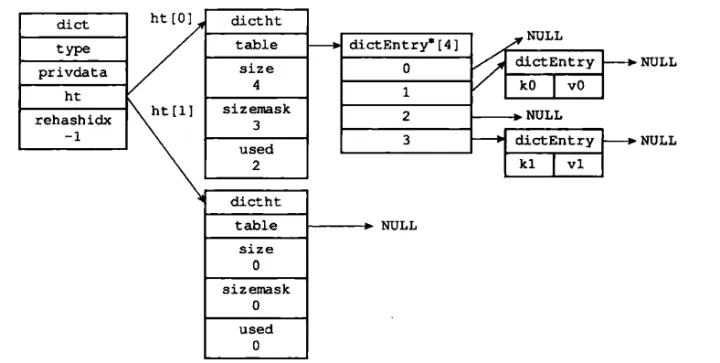
1. Redis字典
深入理解Redis 数据结构—字典 - 知乎 (zhihu.com)
可以这样理解:Redis的字典就是java7的HashMap,即哈希表+链表
Redis字典使用的哈希表结构如下:redis/dict.h at 2.6 · redis/redis (github.com)
typedef struct dictht {
// table 数组
dictEntry **table;
// 哈希表的大小
unsigned long size;
// 等于size-1,用于计算索引值, 这里说明size肯定是2的幂
unsigned long sizemask;
// 已有的键值对数量
unsigned long used;
} dictht;
c++
dictEntry就是哈希节点了:redis/dict.h at 2.6 · redis/redis (github.com)
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
c++
Redis中的字典则由dict组成:redis/dict.h at 2.6 · redis/redis (github.com)
typedef struct dict {
// 类型特定的函数,提供增删改查等功能
dictType *type;
// 私有函数
void *privdata;
// 哈希表, 这里的二维是后面用来扩容的
dictht ht[2];
// rehash 索引,记录了当前扩容的进度
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 用来记录当前运行的安全迭代器数,当不为0的时候表示有安全迭代器正在执行,这时候就会暂停rehash操作
int iterators; /* number of iterators currently running */
} dict;
c++
2. Redis扩容与缩容
我们用ht[0].used/ht[0].size表示负载因子
2.1 扩容
-
如果没有fork子进程在执行RDB或者AOF的持久化,一旦满足负载因子大于等于1,此时触发扩容;
-
如果有fork子进程在执行RDB或者AOF的持久化时,则需要满足负载因子大于5,此时触发扩容。
Redis在扩容时使用的是渐进式哈希,即每次值移动一部分的数据到新的哈希表中。
在字典dict中,dict.ht[0]代表旧的哈希表,dict.ht[1]代表新的哈希表,每次扩容时会将容量乘2,同时dict.rehashidx代表rehash的进度,表示dict.ht[0]中,小于该索引的值都已经被移动到dict.ht[1]中了,此时需要在dict.ht[1]中进行相关的增删改查操作,反之则在dict.ht[0]中进行。
在扩容期间,每次进行增删改查都会将dict.rehashidx加一,并进行相关的rehash操作。
在扩容完毕后,将dict.ht[0]指向dict.ht[1],并删除旧的哈希表。
2.2 缩容
当负载因子小于0.1时,Redis就会对哈希表进行收缩操作。
相关操作和扩容一样,在dict.ht[1]处创建新的哈希表,之后再渐进式rehash。
2.3 其它问题
假如在rehash扩容的时候,我们一直插入,会不会导致再次扩容呢?
假设此时哈希表容量为n,元素数量为n,在扩容哈希表容量后变为2n,而对于Redis来说,完成rehash需要2n - n = n次操作,所以我们最多进行n次插入,插入完后元素数量也变为2n,再次触发扩容。
对于负载因子为5的时候,假设此时哈希表容量为n,元素数量为5n + 1,扩容后哈希表容量为2n,同样我们可以插入n个元素,此时元素数量变为6n + 1,负载因子为(6n + 1) / 2n约等于3,此时不会触发扩容。
3. 字典遍历
3.1 全遍历
使用如下指令就会执行全遍历,返回所有的key:
keys *shell
优点:
- 返回的key不会重复
缺点:
- 在遍历完前会阻塞服务器
迭代器结构:
typedef struct dictIterator {
dict *d; //迭代的字典
int index; //当前迭代到Hash表中哪个索引值
int table, safe; //table用于表示当前正在迭代的Hash表,即ht[0]与ht[1],safe用于表示当前创建的是否为安全迭代器
dictEntry *entry, *nextEntry;//当前节点,下一个节点
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;//字典的指纹,当字典未发生改变时,该值不变,发生改变时则值也随着改变
} dictIterator;
c++
3.3.1 安全迭代器和非安全迭代器
Redis源码学习——安全迭代器和非安全迭代器(一)_damanchen的博客-CSDN博客
Redis源码学习——安全迭代器和非安全迭代器(二)_damanchen的博客-CSDN博客
跋山涉水 —— 深入 Redis 字典遍历 - 知乎 (zhihu.com)
安全迭代器:
- 迭代的时候不能rehash,可以进行过期键的删除
非安全迭代器:
- 迭代的时候可以rehash,但是不能进行删除等操作(字典只读),通过
fingerprint字段来判断字典是否发生变动
3.2 间接遍历
使用scan命令可以间接遍历,这个命令每次会返回一个下一个需要遍历的索引值:
redis 127.0.0.1:6379> scan 0 1) "17" 2) 1) "key:12" 2) "key:8" 3) "key:4" 4) "key:14" 5) "key:16" 6) "key:17" 7) "key:15" 8) "key:10" 9) "key:3" 10) "key:7" 11) "key:1" redis 127.0.0.1:6379> scan 17 1) "0" 2) 1) "key:5" 2) "key:18" 3) "key:0" 4) "key:2" 5) "key:19" 6) "key:13" 7) "key:6" 8) "key:9" 9) "key:11"shell
优点:
- 一次只返回部分内容,响应较快,不会较长时间阻塞服务器
缺点:
- 可能会返回重复的值
redis scan 命令底层原理(为什么会重复扫描?)_redis scan命令原理_柏油的博客-CSDN博客
这里第一次看可能会有这个疑问,我们打个比方:
遍历顺序:00 -> 10 -> 01 -> 11
若正好遍历到10时扩容完毕了,则新顺序为:
000 -> 100 -> 010 -> 110 -> 001 -> 101 -> 011 -> 111
此时我们在第三个位置,即010那里。
这时候可能就有疑问了:100那里不就遍历不到了吗?这不是丢数据了吗?
但这样其实是想多了,我们来看000和100,假如哈希表长度为4时,这两个索引下的元素会落到哪个哈希表下?
很明显,这两个位置的元素都会落到00这个索引的下面,因为哈希表长度为4时,索引位置的取法就是和0x11做与操作,而000和100低两位相同,所以它们俩在之前就在00处,以链表的形式组合在了一起,当遍历到10时,100也肯定被遍历了。
总结一下就是scan命令会在哈希表缩容的时候造成数据重复,在rehash的期间也会造成重复。
在rehash期间调用scan,Redis会先扫小表,假如最终索引为v,然后会接着在大表中从v开始扫。
4. 五大基本数据类型
在看数据类型前,我们再回顾一下entry的结构:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
c++
有没有发现一个问题:这个v代表值,那么这个值是个什么东西??
这里其实是C语言的union,可以让多个变量使用同一个内存空间:C/C++ union 使用教程 (常见操作与缺陷) - 知乎 (zhihu.com)
你可以这样理解:这里的v即有三种类型,即void*、uint64_t(64位无符号整数)、int64_t(64位有符号整数)。
对应void*你可以理解为Java中的Object类型,用它做参数的话就可以传入任意对象,更详细的信息可以看这篇博客:void*(指针)的类型转换-专讲_void*转换_NeverLate_gogogo的博客-CSDN博客
一般情况下void*都是指向redisObject :redis/README.md at cb1717865804fdb0561e728d2f3a0a1138099d9d · redis/redis (github.com)
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
};
c++
-
type:没啥好说的,每种数据结构的标识符 -
encoding:编码-
以string来说,就有三种:
int,embstr,raw:127.0.0.1:6379> SET counter 1 OK 127.0.0.1:6379> OBJECT ENCODING counter "int" 127.0.0.1:6379> SET name "Tom" OK 127.0.0.1:6379> OBJECT ENCODING name "embstr" 127.0.0.1:6379> SETBIT bits 1 1 (integer) 0 127.0.0.1:6379> OBJECT ENCODING bits "raw"shell
-
-
lru:给Redis做内存淘汰用 -
refcount:引用计数,这个值为0的时候这个对象会被清除 -
ptr:指向对象的实际表示,可能有多个指向同一个对象,一般还要配合encoding判断
4.1 String
Redis 的字符串是动态字符串,是可以修改的字符串,可以勉强理解为Java里的StringBuilder。
当字符串需要扩容时,有如下两种情况:
- 当字符串长度小于 1M 时,扩容都是加倍现有的空间
- 超过 1M,扩容时一次只会多扩 1M 的空间
字符串最大长度为512MB。 数据结构:redis/sds.h at cb1717865804fdb0561e728d2f3a0a1138099d9d · redis/redis (github.com)
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
c++
我们可以发现,字符串结构体基本由len(已使用的长度)、alloc(最大长度/分配的长度)、flags(标志信息)、buf(字符串内容)组成。
字符串拼接:redis/sds.c at cb1717865804fdb0561e728d2f3a0a1138099d9d · redis/redis · GitHub
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
// 内存不足
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
c++
要懂redis,首先得看懂sds(全网最细节的sds讲解) - 知乎 (zhihu.com)
4.2 Hash
Redis之Hash数据结构底层原理_redis hash原理_不要迷恋发哥的博客-CSDN博客
4.2.2 hashtable
hashtable就和Redis最外层的字典是差不多的。
4.3 List
对于List同样也有两种编码:
- ziplist:压缩列表
- linkedlist:双向链表
满足如下条件时,压缩列表会被转换为双向链表:
- 试图往列表新添加一个字符串值,且这个字符串的长度超过 server.list_max_ziplist_value (默认值为 64 )
- ziplist 包含的节点超过 server.list_max_ziplist_entries (默认值为 512 )
Redis列表list 底层原理 - 知乎 (zhihu.com)
4.2.1 ziplist
ziplist的运作方式类似于一个队列:
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->| size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte +---------+--------+-------+--------+--------+--------+--------+-------+ component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend | +---------+--------+-------+--------+--------+--------+--------+-------+ ^ ^ ^ address | | | ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END | ZIPLIST_ENTRY_TAILtext
| 字段 | 类型 | 说明 |
|---|---|---|
| zlbytes | uint32_t | 整个ziplist占用的内存字节数。 |
| zltail | uint32_t | 到达ziplist表尾节点的偏移量。 |
| zllen | uint16_t | ziplist中节点的数量。 |
| entryX | ? | ziplist的各个节点。 |
| zlend | uint8_t | 常量0b111111,用于标记ziplist末尾。 |
每个entry的结构是这样的:
+-----------------------+----------+---------+ | previous_entry_length | encoding | content | +-----------------------+----------+---------+text
previous_entry_length:前面一个节点的长度(字节)。若前面一个节点的长度小于254字节,则该属性占1个字节的宽度,反正则是占5个字节的宽度,第一个字节是常量0xFE(254)
encoding:记录content的类型
content:保存节点的值
我们可以发现ziplist不能从头开始遍历,因为每个节点的长度都是不一样的,在遍历的时候需要根据zltail的值从尾部开始向前遍历。
4.4 Set
Set拥有两种编码:
- intset:使用数组维护set,数组是有序的
- hashtable:直接使用哈希表维护set
满足如下条件时intset将会被转换成hashtable:
- 保存了非整型的值
- 元素数量超过了512个
4.4.1 intset
数据结构:
typedef struct intset {
// 这个编码用来决定contents的大小
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
c++
redis/intset.h at 971b177fa338fe06cb67a930c6e54467d29ec44f · redis/redis (github.com)
面试官:说说Redis中Set数据类型的底层实现 - 掘金 (juejin.cn)
4.5 zset(Sorted Set)
zset有两种实现:
- zipList:压缩列表
- skipList:跳表
满足如下条件时zipList会转换成skipList:
- 节点数量大于等于128(server.zset_max_ziplist_entries)
- 节点的长度大于等64(server.zset_max_ziplist_value)
Redis 跳跃表skiplist(深入理解,面试再也不用怕)_redis skiplist_妖四灵.Shuen的博客-CSDN博客
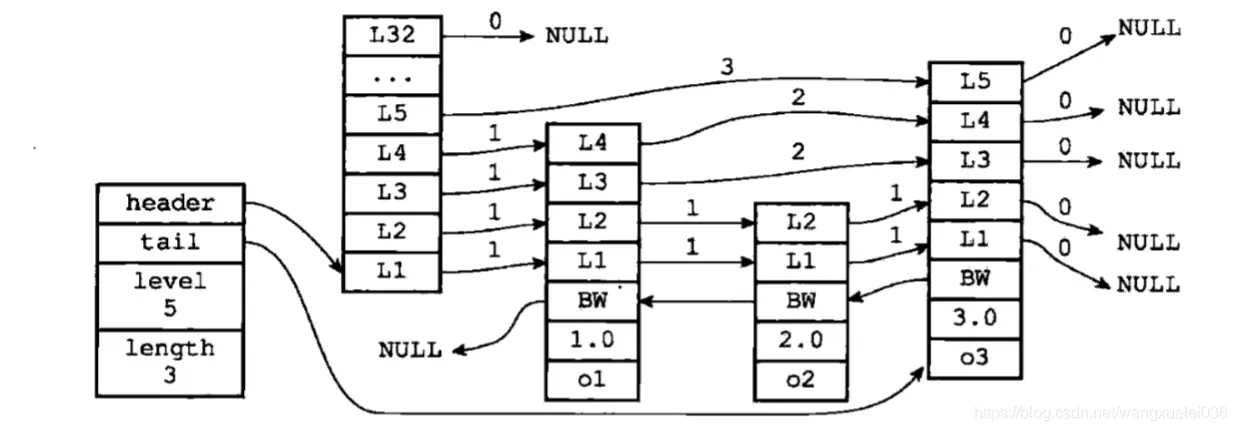
- header:指向跳跃表的表头节点
- tail:指向跳跃表的表尾节点
- level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)
- length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)
节点数据结构:
typedef struct zskiplistNode {
// 当前保存的值
sds ele;
// 分值,用于排序
double score;
// 前一个节点
struct zskiplistNode *backward;
// 当前层节点
struct zskiplistLevel {
struct zskiplistNode *forward;
// 跳表的跨度
unsigned long span;
} level[];
} zskiplistNode;
c++
redis/server.h at 971b177fa338fe06cb67a930c6e54467d29ec44f · redis/redis (github.com)
// 跳表
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
// 跳表的长度
unsigned long length;
// 最高层数
int level;
} zskiplist;
// zset数据结构
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
c++
5. Redis持久化方式
5.1 RDB
RDB即Redis Database,它会将Redis某一时刻的数据以文件的形式全量备份到磁盘。
Redis提供了两个指令来生成RDB,一个是SAVE,这个命令会阻塞主线程,直到RDB生成完毕。
另外一个则是BGSAVE,这时会fork一个子进程去专门负责写入RDB。
在读取数据时用到了写时复制(COW)技术,fork创建出的子进程,与父进程共享内存空间。也就是说,如果子进程不对内存空间进行写入操作的话,内存空间中的数据并不会复制给子进程,这样创建子进程的速度就很快了!
LInux fork的写时复制(copy on write)_fork写时复制_富士康质检员张全蛋的博客-CSDN博客
5.2 AOF
AOF即Append Only File,它会记录在redis服务器上执行过的命令来实现持久化的目的。
Redis详解(七)------ AOF 持久化 - YSOcean - 博客园 (cnblogs.com)
Redis默认每秒执行一次AOF的写入。
5.2.1 AOF重写
为了防止AOF文件过大,当AOF的文件大小超过设定的阈值后,Redis就会启动AOF的文件压缩。
压缩前:
sadd animals "cat" sadd animals "dog" sadd animals "cat" sadd animals "lion"shell
压缩后:
sadd animals "cat" "dog" "lion"shell
6. 内存
6.1 内存过期策略
Redis对于过期的key有两种删除策略:
- 定期删除
- 惰性删除
6.1.1 定期删除
Redis会将每个设置了过期时间的key放到一个独立的字典中,以后会定期按照某种算法来遍历里面的key。
默认每秒进行10次扫描,每次会随机选取一些key,然后删除其中过期的key,若某次删除的数量超过了选取的1/4,则会重复这一步骤。
6.1.2 惰性删除
在客户端访问某个key时,若这个key过期,则会将其删除。
6.2 内存淘汰策略
当没有可以被删除的key,且Redis内存不足时,此时会根据内存淘汰策略删除一些没有过期的key。
-
noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
-
allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
-
volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
-
allkeys-random:加入键的时候如果过限,从所有key随机删除
-
volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
-
volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
-
volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
-
allkeys-lfu:从所有键中驱逐使用频率最少的键
关于LRU和LFU,在redisObject里会保存相关的参数:
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
};
c++
redis/README.md at cb1717865804fdb0561e728d2f3a0a1138099d9d · redis/redis (github.com)
- 当使用LRU算法时,
lru整个值都用来表示相关访问时间。 - 当使用LFU算法时,低8位表示访问频率,高16位表示上一次访问时间
6.2.1 LRU
LRU即Least Recently Used-最近最少使用算法。
LRU会维护一个双向链表,对于新加入的数据或者最近被访问的数据,它们会被存/移动到链表头部,当内存不足的时候删除链表尾部的数据。
优点:
- 好实现
缺点:
- 冷数据可能会把热数据顶掉
6.2.2 LFU
LFU即Least Frequently Used-最不经常使用。其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
Redis的LFU和上面的LFU有一些不一样,一般的LFU有如下缺点:
- 新增的缓存容易被删除
而Redis在此基础上会将每个数据的访问次数设置为5,每次访问会根据其上次访问时间扣除一定的访问次数,然后再根据生成的一个随机数,决定是否对访问次数字段加一:
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
// 访问次数越多,加一的概率越小
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
c++
其中server.lfu_log_factor默认为10。
因为访问计数器的长度为8位,最大为255,如果每次访问都加一,很可能会导致溢出。
16 | LFU算法和其他算法相比有优势吗? (geekbang.org)
7. Redis集群
一文搞懂 Redis 的三种集群方案 - 腾讯云开发者社区-腾讯云 (tencent.com)
Redis支持三种集群方案:
- 主从复制
- 哨兵模式
- Cluster模式
7.1 主从复制
主从复制主要由一个主数据库与一个或多个从数据库实例组成。
客户端可对主数据库进行读写操作,对从数据库进行读操作,主数据库写入的数据会实时自动同步给从数据库。
具体工作机制为:
- slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave保存快照,并使用缓冲区记录保存快照这段时间内执行的写命令
- master将保存的快照文件发送给slave,并继续记录执行的写命令
- slave接收到快照文件后,加载快照文件,载入数据
- master快照发送完后开始向slave发送缓冲区的写命令,slave接收命令并执行,完成复制初始化
- 此后master每次执行一个写命令都会同步发送给slave,保持master与slave之间数据的一致性
优点:
- master能自动将数据同步到slave,可以进行读写分离,分担master的读压力
- master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
缺点:
-
难以支持在线扩容,Redis的容量受限于单机配置
-
master宕机,如果宕机前数据没有同步完,则切换IP后会存在数据不一致的问题
-
不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复
7.2 哨兵模式
哨兵模式基于主从复制模式,只是引入了哨兵来监控与自动处理故障。
哨兵顾名思义,就是来为Redis集群站哨的,一旦发现问题能做出相应的应对处理。其功能包括:
- 监控master、slave是否正常运行
- 当master出现故障时,能自动将一个slave转换为master(大哥挂了,选一个小弟上位)
- 多个哨兵可以监控同一个Redis,哨兵之间也会自动监控
Redis哨兵(Sentinel)模式 - 简书 (jianshu.com)
优点:
- 哨兵模式基于主从复制模式,所以主从复制模式有的优点,哨兵模式也有
- 哨兵模式下,master挂掉可以自动进行切换,系统可用性更高
缺点:
- 同样也继承了主从模式难以在线扩容的缺点,Redis的容量受限于单机配置
- 需要额外的资源来启动sentinel进程,实现相对复杂一点,同时slave节点作为备份节点不提供服务
7.3 Cluster模式
Cluster采用无中心结构,它的特点如下:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的fail是通过集群中超过半数的节点检测失效时才生效
- 客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
Cluster模式的具体工作机制:
- 在Redis的每个节点上,都有一个插槽(slot),取值范围为0-16383
- 当我们存取key的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
- 为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点
- 当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了
Cluster模式集群节点最小配置6个节点(3主3从,因为需要半数以上),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。