筛选唯一值
关于这个操作,网上的操作要么是直接用自带的 删除重复值,或者 高级筛选 直接创建一个新的表格。但是这俩个操作有一个最大的问题:重复的值都被删除了。
假如我有一个列保存文件名,另外一个列保存文件中的一些关键内容,一个文件中可能有多个关键内容,也就是一个文件有多行。我删除重复值只是想看一下有哪些文件,看完又需要恢复,那么这个操作就非常不友好了。
这个时候就要请出我们的 COUNTIF 了。
先直接看效果:
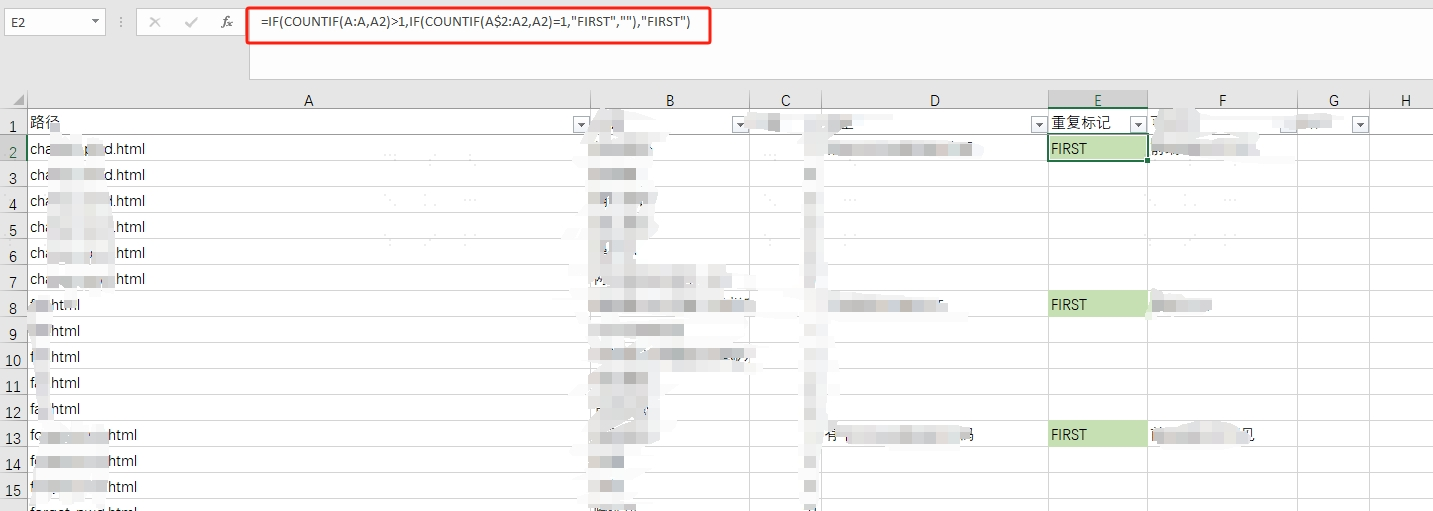
Note这里绿色背景是其它的效果,这里直接忽略就行.
可以发现,所有项目的第一个都会被标记出来,之后我们直接使用普通的 筛选,筛选出值为 FIRST 的行就可以了。
使用到的函数:=IF(COUNTIF(A:A,A2)>1,IF(COUNTIF(A$2:A2,A2)=1,"FIRST",""),"FIRST")
COUNTIF(range, criteria): 计算区域内满足条件的单元格数量。
range: 选中一个范围criteria: 判断条件,可以是一个字符串,返回单元格内等于该字符串的数量。也可以是一个判断,例如>5,则判断range内大于5的单元格数量。
IF(condition, val1, val2): 如果满足条件,则返回 val1 否则返回 val2。
- condition: 判断条件
- val1: 为真的值
- val2: 回退值
所以我们这里的思路就是:对于一个单元格,统计它上面和它自己所有单元格的范围内,值和自己相等的单元格数量。当值为 1 时,就说明该单元格的值是所有重复的值中的第一个,这时我们给他打上一个标记,就可以利用 Excel 的筛选功能就可以做到不删除数据,又能筛选出重复的第一个了。
碰到的坑
由于我们的判断条件是当前单元格和它上面的区域,也就是说如果我们对单元格进行排序或者其它操作,那么我们的标记就会发生变动。如果你只想给重复的第一个值进行一些其它的修改,那么可能一次排序就会毁掉你的所有修改。
这个问题的解决方法也很简单,我们只需要给所有行新建一列,名字叫做序号,值从任意值开始递增,在顺序被我们打乱后,只需要按照序号进行排序就可以恢复到原来的状态。
待补坑
挖个坑在这里,后面碰到了新的需要再来写。