一主二从
Note参考: https://blog.csdn.net/qq_41786285/article/details/109304126
准备配置
mkdir -p /data/mysql/ mkdir /data/mysql/mysql20001 mkdir /data/mysql/mysql20002 mkdir /data/mysql/mysql20003shell
mysql20001 是主数据库,mysql20002 和 mysql20003 是从数据库。
修改主节点配置文件(/data/mysql/my1.cnf):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 # 可选 binlog_format = mixed # 下面的配置是必须的 server-id = 1 log_bin = mysql-bin binlog_ignore_db=information_schema,performance_schema,mysql,syscnf
修改从节点配置(/data/mysql/my2.cnf):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 # 下面的配置是必须的 server-id = 2 relay-log = relay-log-bin relay-log-index = slave-relay-bin.indexcnf
Important记住配置另外一个从库的时候需要修改 server-id
最后修改目录权限:
useradd mysql groupadd mysql chown -R mysql /data/mysql chgrp -R mysql /data/mysqlshell
启动容器
Important可以使用我自己上传的镜像:
docker pull ccr.ccs.tencentyun.com/icebing-repo/mysql:5.7.42
ID=1 docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42shell
注意参数中的 -u 27:27,这里是使用了 uid:gid 的格式,使用其它格式会导致权限不足:
2024-12-03 14:36:24+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 5.7.42-1.el7 started. 2024-12-03 14:36:24+00:00 [Note] [Entrypoint]: Initializing database files mysqld: Can't create directory '/var/lib/mysql/' (Errcode: 17 - File exists) 2024-12-03T14:36:24.891299Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details). 2024-12-03T14:36:24.893084Z 0 [ERROR] Abortinglog
查看 uid 和 gid:
[root@localhost mysql]# id mysql uid=27(mysql) gid=27(mysql) groups=27(mysql)shell
同样的方式启动另外两台从节点。
从节点加入集群
登录主节点执行:
grant replication slave on *.* to 'myslave'@'172.17.0.%' identified by '123456';
flush privileges;
sql
注意这里的 ip 地址,容器默认情况下是桥接模式,容器的 ip 不是宿主机的 ip,具体 ip 网段可以用下面的命令看:
docker inspect mysql20002 | grep Networks -A 16shell
找到 Gateway 字段,单独使用这个 ip 或者直接使用对应的网段。
查看主节点状态:
# 主库执行
show master status;
sql

这里需要记住上面的 File 和 Position,之后在从节点中执行下面的 sql 来加入集群:
# 从库执行
change master to master_host ='10.77.0.38',
master_port = 20001,
master_user ='myslave',
master_password ='123456',
master_log_file ='mysql-bin.000004',
master_log_pos =154;
show slave status;
start slave;
sql
这里我们先只让一台加进去,后面一台我们待会尝试中途加入。
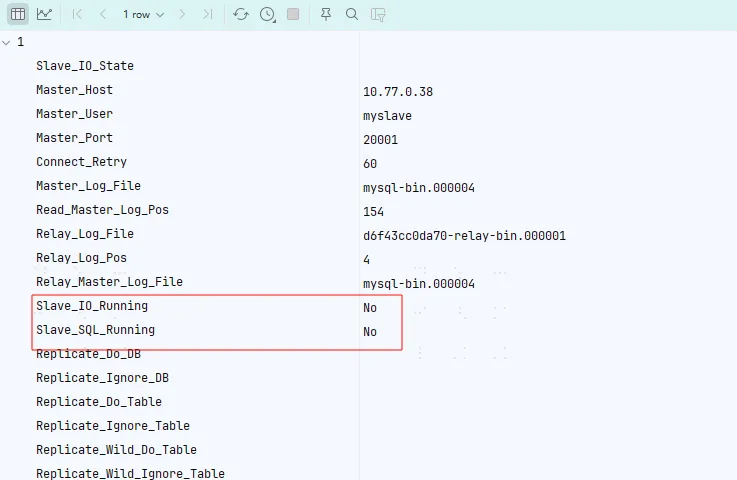
这里等到打框框的这两个值都变成 YES 就完成了。但是我这里把配置搞错了...导致一直加不进去,所以这里额外研究了一下节点怎么退出集群。
节点退出集群
使用下面的命令之一退出集群
# 停止从主节点的同步,直到使用 START SLAVE
STOP SLAVE;
# 删除同步的内容
RESET SLAVE;
sql
部分情况下由于初始的错误配置可能导致停不掉,这时候就直接强制停止从节点重新部署一个就行了,对主节点没有影响的。
测试从节点
在主库执行下面的 sql:
create database slave_test;
use slave_test;
CREATE table slave_data(
id varchar(20) primary key ,
tm timestamp
);
INSERT INTO slave_data value ('1', CURRENT_TIMESTAMP());
sql
然后可以查看从节点是否创建相关的数据。
从节点扩容
Note参考: https://blog.csdn.net/anddyhua/article/details/116240478
我们这里留了一台节点还没有加入集群,这里我们专门来测试从节点的水平扩容。这里我们使用 xtrabackup 来进行备份。
首先下载 xtrabackup,这里 Mysql 5.7 只能使用 2.4 版本的。下载完成后解压,进入 bin 目录,执行下列命令进行备份:
./xtrabackup --backup --target-dir=/data/mysql/backup/bakup_`date +"%F_%H_%M_%S"` --user=root --host=10.77.0.38 --port=20001 --password=123456 --datadir=/data/mysql/mysql20001shell
备份完成后查看目录:
[root@localhost bakup_2024-12-05_00_28_08]# ll total 77876 -rw-r----- 1 root root 487 Dec 5 00:28 backup-my.cnf -rw-r----- 1 root root 661 Dec 5 00:28 ib_buffer_pool -rw-r----- 1 root root 79691776 Dec 5 00:28 ibdata1 drwxr-x--- 2 root root 4096 Dec 5 00:28 mysql drwxr-x--- 2 root root 8192 Dec 5 00:28 performance_schema drwxr-x--- 2 root root 64 Dec 5 00:28 slave_test drwxr-x--- 2 root root 8192 Dec 5 00:28 sys -rw-r----- 1 root root 21 Dec 5 00:28 xtrabackup_binlog_info -rw-r----- 1 root root 138 Dec 5 00:28 xtrabackup_checkpoints -rw-r----- 1 root root 587 Dec 5 00:28 xtrabackup_info -rw-r----- 1 root root 2560 Dec 5 00:28 xtrabackup_logfileshell
可以发现几乎是和 mysql 数据目录一样的结构。之后我们将备份的内容复制到第二个从节点的数据目录中(/data/mysql/mysql20003)。这里需要注意权限问题,复制过来后需要把权限给 mysql 用户。
启动从库(和之前相同的命令):
ID=3 docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42shell
由于我们在备份的过程中,主节点仍然可以写入数据,所以导致我们备份的数据不一定是最新的,所以在加入集群的时候不能直接使用 show master status 中的 binlog 位置。这里我们需要根据备份目录中 xtrabackup_info 文件来确定具体的位置:
[root@localhost mysql20003]# cat xtrabackup_info uuid = c333e3de-b25c-11ef-81e2-0242ac110002 name = tool_name = xtrabackup tool_command = --backup --target-dir=/data/mysql/backup/bakup_2024-12-05_00_28_08 --user=root --host=10.77.0.38 --port=20001 --password=... --datadir=/data/mysql/mysql20001 tool_version = 2.4.29 ibbackup_version = 2.4.29 server_version = 5.7.42-log start_time = 2024-12-05 00:28:08 end_time = 2024-12-05 00:28:15 lock_time = 4 binlog_pos = filename 'mysql-bin.000006', position '154' innodb_from_lsn = 0 innodb_to_lsn = 12232730 partial = N incremental = N format = file compact = N compressed = N encrypted = Nshell
这里可以看到 binlog_pos 的值,表示当前 binlog 读到了哪里,我们根据这个值来加入主节点:
# 从库执行
change master to master_host ='10.77.0.38',
master_port = 20001,
master_user ='myslave',
master_password ='123456',
master_log_file ='mysql-bin.000006',
master_log_pos =154;
start slave;
show slave status;
sql
最终等待 SLAVE_IO 和 SALVE_SQL 都变成 YES, 从库就加入成功了。
主主架构
主主架构是指系统中有两个 mysql 主数据库,它们相互读写,互相同步数据。相比于单纯的一主多从,主主架构最大的优势就是提供了主节点的高可用
关于读写分离
应用层读写分类
对于简单的集群,例如上面的一主两从,我们可以使用下面的方式在应用的层面实现读写分离:
jdbc:mysql:replication://[source host][:port],[replica host 1][:port][,[replica host 2][:port]]...[/[database]] [?propertyName1=propertyValue1[&propertyName2=propertyValue2]...]plaintext
仅 Java 可用:官方文档。
但是有些语言的驱动可能没有提供读写分离的功能,这个时候可以选择自己在应用层实现。可以参考上面 mysql 文档中的实现,当关闭了只读模式和自动提交,那么后续的 sql 都发送到主节点,否则发送到从节点。
使用中间件实现读写分离
如果不想写代码,可以通过加一个中间件来实现。目前我可以找到的,距离上一次提交最近的中间件是:mycat。
其它的这些全都没有维护了:
个人还是推荐直接在应用层解决吧,毕竟这里还要单独启动一个服务,搞不好中间件就成性能瓶颈了?
多主架构
架构图:
图是自动生成的,可能会有点丑
主主架构相比与一主多从架构,最大的区别就是提供了主节点的高可用,搭配 keepalived 等其它工具,可以快速切换主节点,大大降低了系统的恢复时间。而一主多从架构,只能手动切换主节点,容灾能力低。
但这种架构有下面的缺点:
- 假设上图中的 mysql20001 挂了后,keepalived 自动将写流量切换到 mysql20002 上。当 mysql20001 恢复后重新加入集群,如果不做任何调整,此后将没有任何流量会发送到 mysql20001,除非 mysql20002 挂了或者手动切换主备。
- 主节点挂了后,如果备用的主节点数据还没同步完或者还没开始同步,则会导致数据不一致,这里可以通过修改复制方式来缓解或解决。
准备配置文件
这里我们还是用之前一主两从的配置,先重置掉所有数据:
docker rm mysql20001 -f
docker rm mysql20002 -f
docker rm mysql20003 -f
rm -rf /data/mysql/mysql20001/*
rm -rf /data/mysql/mysql20002/*
rm -rf /data/mysql/mysql20003/*
bash
修改 /data/mysql/my1.cnf,添加下面的内容:
auto_increment_increment=1 auto_increment_offset=1cnf
修改 /data/mysql/my2.cnf,添加下面的内容:
auto_increment_increment=2 auto_increment_offset=2 log_bin=mysql-bin binlog_format=mixed binlog_ignore_db=information_schema,performance_schema,mysql,sys log_slave_updates=ONcnf
这里出现了两个个新的参数:auto_increment_increment、auto_increment_offset 作用分别如下:
auto_increment_increment: 自增主键每次增长多少auto_increment_offset: 自增主键从哪里开始增长- log_slave_updates: 是否将副本(从)服务器从副本源服务器收到的更新写到 binlog 中,默认关闭(mysql8 默认开启,坑了我一波,一开始看错文档了)。这个配置常用于级联架构,例如你可以给一个从库开启这个,然后把这个从库"当成主库",给它加几个从库,达到类似于
A -> B -> C的数据库架构。
启动容器
相同的命令启动容器:
ID=1
docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42
ID=2
docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42
ID=3
docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42
bash
在 mysql20001 和 mysql20002 上创建账号:
grant replication slave on *.* to 'myslave'@'172.17.0.%' identified by '123456';
sql
网段还是要用容器的网段,不是宿主机的!最后相互连接,注意参数需要根据实际情况修改:
change master to master_host ='10.77.0.38',
master_port = 20001,
master_user ='myslave',
master_password ='123456',
master_log_file ='mysql-bin.000004',
master_log_pos =154;
start slave ;
show slave status ;
sql
测试同步,任意主数据库上执行:
create database slave_test;
use slave_test;
CREATE table slave_data(
id varchar(20) primary key ,
tm timestamp
);
INSERT INTO slave_data value ('1', CURRENT_TIMESTAMP());
sql
在另外一个数据库执行:
use slave_test;
INSERT INTO slave_data value ('2', CURRENT_TIMESTAMP());
sql
可以发现两个主库都可以写,并且可以相互同步,而且没有出现任何报错。
最后使用相同的方法,让从库连接上备用主库,进行读写分离(注意加入备用主库时的 pos 需要用最开始的位置或者手动使用 xtrabackup 进行备份后再加入也可以)
最后我们只需要用 keepalived 给两台主库配置上高可用,我们的主主架构就完成了!
总结
至此,我们已经学会 mysql 集群中最基础的部署架构了,在 mysql 中,主从只是一个相对的概念,一个节点既可以是"主"又可以"从",例如我们在主主中提过一嘴的级联架构:
A -> B -> C | -> D | -> Eplaintext
其中 A 为一个主库,B、C、D 和 E 都是从库,但是 C、D、E 的"主库" 是 B,这种架构可以分担 A 的 IO 压力,让写操作更快。
另附配置文件(my1.cnf):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 server_id=1 log_bin=mysql-bin binlog_format=mixed log-slave-updates=true binlog_ignore_db=information_schema,performance_schema,mysql,sys auto_increment_increment=1 auto_increment_offset=1cnf
my2.cnf:
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 relay-log = relay-log-bin relay-log-index = slave-relay-bin.index server-id = 2 auto_increment_increment=2 auto_increment_offset=2 log_bin=mysql-bin binlog_format=mixed binlog_ignore_db=information_schema,performance_schema,mysql,sys log_slave_updates=ONcnf
my3.cnf 没有什么好看的,就是寻常的从库配置。
循环复制问题
我们前面提到开启 log_slave_updates 后, mysql 会把从副本服务器同步的数据也写到自己的 binlog 里面,那么会不会出现这种情况:假设 A 和 B 两个主库都开启这个配置 A 写入一条数据, B 同步后写入 binlog, 然后 A 发现 B binlog 写了新东西,然后去同步,同步完后 B 发现 A 又写了新东西...
就和之前说的一样, mysql 中的主从都是相对的, 所以 mysql 也没有限制这种循环依赖(实际不会这么用,有点像吃饱了没事干...)。
这里如果感兴趣可以自己部署试一下,实际的效果是并不会出现上面的无限同步效果,但是开启后两台主库的 binlog 状态(show master status)会保持相同,只有一台开的时候是不会相同的。
那么 mysql 怎么避免的呢?很简单,判断 binlog 的 server-id,如果是自己的就不同步。
例如在 server-id 为 1 的主库执行下面的 sql 语句:
INSERT INTO slave_data value ('6', CURRENT_TIMESTAMP());
sql
使用 mysqlbinlog 查看 binlog(无关的内容被省略):
#241209 21:17:24 server id 1 end_log_pos 606 CRC32 0xec624c47 Anonymous_GTID last_committed=1 sequence_number=2 rbr_only=no SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/; # at 606 #241209 21:17:24 server id 1 end_log_pos 705 CRC32 0xb3303223 Query thread_id=5 exec_time=0 error_code=0 SET TIMESTAMP=1733750244/*!*/; BEGIN /*!*/; # at 705 #241209 21:17:24 server id 1 end_log_pos 897 CRC32 0x54a64039 Query thread_id=5 exec_time=0 error_code=0 SET TIMESTAMP=1733750244/*!*/; /* ApplicationName=IntelliJ IDEA 2024.3 */ INSERT INTO slave_data value ('5', CURRENT_TIMESTAMP()) /*!*/; # at 897 #241209 21:17:24 server id 1 end_log_pos 928 CRC32 0x941d43ff Xid = 77 COMMIT/*!*/; SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/; DELIMITER ; # End of log file /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;log
可以发现 binlog 是带上了 server-id 的,这样就可以完美避免上面的循环同步的问题了。
主从复制开启 GTID
GTID (Golobal Transaction ID) 可以简单理解为使用雪花算法计算的一个全局唯一 id。
再简单理解一点就是:
- 全局唯一 id
- 递增
格式为:数据库UUID:XID。
它的主要作用就是方便我们创建从库,我们在使用 change master 命令时只需要将 master_auto_position 设置为 1 就可以了,不再需要我们去看主库的状态了。
相当于把 binlog file 和 position 这种不连续的值转换成连续的 id, 只需要告诉 mysql id 从哪里开始就行了, mysql 可以自己推断出下一个 id 然后去同步。
这个 id 直接保存在表中,使用select * from mysql.gtid_executed就可以看到,所以说我们备份的时候相当于直接记录了起始位置到表中。
配置 GTID
这里我们简单搭个一主一从。主库配置(/data/mysql/my1.cnf):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 server_id=1 log_bin=mysql-bin binlog_format=mixed binlog_ignore_db=information_schema,performance_schema,mysql,sys # 开启 gtid gtid-mode=on enforce_gtid_consistency = oncnf
my2.cnf(就是寻常从库配置):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 server_id=2 # 开启 gtid gtid-mode=on enforce_gtid_consistency = oncnf
启动容器,主库创建账号,这里命令大家翻前面的吧。。。都是一样的,实在懒得写了。
最后,从库加入主库:
change master to master_host ='10.77.0.38',
master_port = 20001,
master_user ='myslave',
master_password ='123456',
master_auto_position = 1;
sql
使用 select @@server_uuid 既可查看当前数据库的 uuid,在主库使用 show global variables like 'gtid_executed' 既可查看当前 gtid 状态:
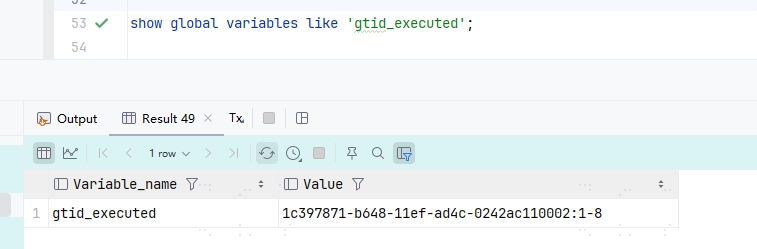
可以发现后面是 1-8,说明有 8 条数据,我们再来看下从库的执行状态,使用 select * from mysql.gtid_executed:
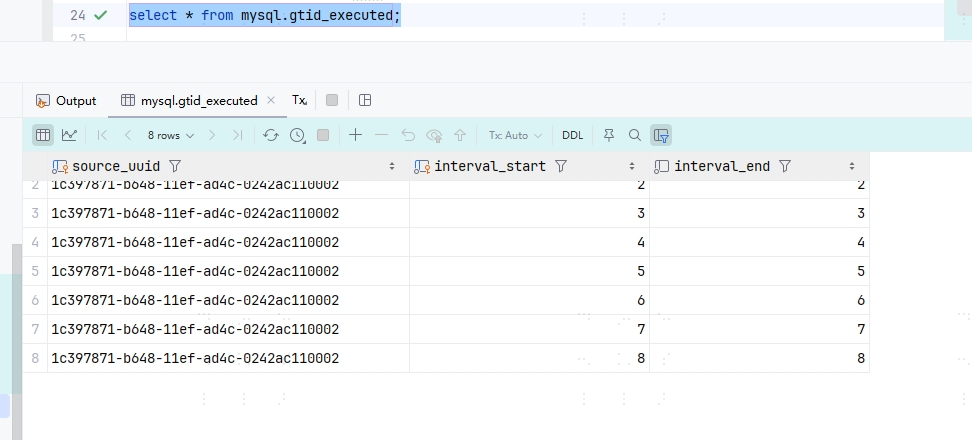
可以发现正好 8 条数据。这里还有一个 interval_end 数据,这里是 mysql 在后续数据量大了之后,会帮我们对数据压缩,具体的实现就是将 start 和 end 设置成一个范围。
最后推荐看一下这个:MySQL 中的集群部署方案,我们前面相当于只介绍了 MySQL Replication 和 MMM, 实际还有很多部署方案。
因为我也没有在生产上实际用过 mysql 集群。。。所以我无法给出一个具体的评价, 但无论如何, 绝大部分架构都是根据MySQL Replication 和 MMM 这两种架构衍生的,所以还是很有必要掌握的。