async/.await 简单入门
async/.await 是 Rust 内置的语言特性,可以让我们用同步的方式去编写异步的代码。
通过 async 标记的语法块会被转换成实现了 Future 特征的状态机。 与同步调用阻塞当前线程不同,当 Future 执行并遇到阻塞时,它会让出当前线程的控制权,这样其它的 Future就可以在该线程中运行,这种方式完全不会导致当前线程的阻塞。
导入下面的包:
[dependencies]
futures = "0.3.30"
toml
使用 async
首先,使用 async fn 语法来创建一个异步函数:
async fn do_something() {
println!("go go go !");
}
rust
需要注意,异步函数的返回值是一个 Future,若直接调用该函数,不会输出任何结果,因为 Future 还未被执行:
fn main() {
do_something();
}
rust
运行后,go go go 并没有打印,同时编译器给予一个提示:warning: unused implementer of Future that must be used,告诉我们 Future 未被使用,那么到底该如何使用?答案是使用一个执行器(executor):
// `block_on`会阻塞当前线程直到指定的`Future`执行完成,这种阻塞当前线程以等待任务完成的方式较为简单、粗暴,
// 好在其它运行时的执行器(executor)会提供更加复杂的行为,例如将多个`future`调度到同一个线程上执行。
use futures::executor::block_on;
async fn hello_world() {
println!("hello, world!");
}
fn main() {
let future = hello_world(); // 返回一个Future, 因此不会打印任何输出
block_on(future); // 执行`Future`并等待其运行完成,此时"hello, world!"会被打印输出
}
rust
使用.await
当在异步函数中调用异步函数时,如果需要等待调用的异步函数执行完成,可以直接使用 .await 来进行等待:
use futures::executor::block_on;
async fn hello_world() {
hello_cat().await;
println!("hello, world!");
}
async fn hello_cat() {
println!("hello, kitty!");
}
fn main() {
let future = hello_world();
block_on(future);
}
rust
输出:
hello, kitty! hello, world!log
但是如果不加 .await:
use futures::executor::block_on;
async fn hello_world() {
// 移出 .await
hello_cat();
println!("hello, world!");
}
async fn hello_cat() {
println!("hello, kitty!");
}
fn main() {
let future = hello_world();
block_on(future);
}
rust
此时编译器会给出警告:
warning: unused implementer of `futures::Future` that must be used --> src/main.rs:6:5 | 6 | hello_cat(); | ^^^^^^^^^^^^ = note: futures do nothing unless you `.await` or poll them ... hello, world!log
hello_cat 方法并没有被执行,编译器也提示需要加上 .await。
总之,在 async fn 函数中使用 .await 可以等待另一个异步调用的完成。但是与 block_on 不同,.await 并不会阻塞当前的线程,而是异步的等待 Future A 的完成,在等待的过程中,该线程还可以继续执行其它的 Future B,最终实现了并发处理的效果。
Future 执行器与任务调度
Future 特征
Future 特征是 Rust 异步编程的核心,毕竟异步函数是异步编程的核心,而 Future 恰恰是异步函数的返回值和被执行的关键。
首先,来给出 Future 的定义:它是一个能产出值的异步计算(虽然该值可能为空,例如 () )。来看看一个简化版的 Future 特征:
trait SimpleFuture {
type Output;
fn poll(&mut self, wake: fn()) -> Poll<Self::Output>;
}
enum Poll<T> {
Ready(T),
Pending,
}
rust
在上一章中,我们提到过 Future 需要被执行器 poll (轮询)后才能运行,通过调用该方法,可以推进 Future 的进一步执行,直到被切走为止。
若在当前 poll 中, Future 可以被完成,则会返回 Poll::Ready(result) ,反之则返回 Poll::Pending, 并且安排一个 wake 函数:当未来 Future 准备好进一步执行时, 该函数会被调用,然后管理该 Future 的执行器(例如上一章节中的 block_on 函数)会再次调用 poll 方法,此时 Future 就可以继续执行了。
如果没有 wake 方法,那执行器无法知道某个 Future 是否可以继续被执行,除非执行器定期的轮询每一个 Future,确认它是否能被执行,但这种作法效率较低。而有了 wake,Future 就可以主动通知执行器,然后执行器就可以精确的执行该 Future。 这种“事件通知 -> 执行”的方式要远比定期对所有 Future 进行一次全遍历来的高效。
用一个例子来说明下。考虑一个需要从 socket 读取数据的场景:如果有数据,可以直接读取数据并返回 Poll::Ready(data), 但如果没有数据,Future 会被阻塞且不会再继续执行,此时它会注册一个 wake 函数,当 socket 数据准备好时,该函数将被调用以通知执行器:我们的 Future 已经准备好了,可以继续执行。
下面的 SocketRead 结构体就是一个 Future:
pub struct SocketRead<'a> {
socket: &'a Socket,
}
impl SimpleFuture for SocketRead<'_> {
type Output = Vec<u8>;
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
if self.socket.has_data_to_read() {
// socket有数据,写入buffer中并返回
Poll::Ready(self.socket.read_buf())
} else {
// socket中还没数据
//
// 注册一个`wake`函数,当数据可用时,该函数会被调用,
// 然后当前Future的执行器会再次调用`poll`方法,此时就可以读取到数据
self.socket.set_readable_callback(wake);
Poll::Pending
}
}
}
rust
这种 Future 模型允许将多个异步操作组合在一起,同时还无需任何内存分配。不仅仅如此,如果你需要同时运行多个 Future 或链式调用多个 Future ,也可以通过无内存分配的状态机实现,例如:
trait SimpleFuture {
type Output;
fn poll(&mut self, wake: fn()) -> Poll<Self::Output>;
}
enum Poll<T> {
Ready(T),
Pending,
}
/// 一个SimpleFuture,它会并发地运行两个Future直到它们完成
///
/// 之所以可以并发,是因为两个Future的轮询可以交替进行,一个阻塞,另一个就可以立刻执行,反之亦然
pub struct Join<FutureA, FutureB> {
// 结构体的每个字段都包含一个Future,可以运行直到完成.
// 等到Future完成后,字段会被设置为 `None`. 这样Future完成后,就不会再被轮询
a: Option<FutureA>,
b: Option<FutureB>,
}
impl<FutureA, FutureB> SimpleFuture for Join<FutureA, FutureB>
where
FutureA: SimpleFuture<Output = ()>,
FutureB: SimpleFuture<Output = ()>,
{
type Output = ();
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
// 尝试去完成一个 Future `a`
if let Some(a) = &mut self.a {
if let Poll::Ready(()) = a.poll(wake) {
self.a.take();
}
}
// 尝试去完成一个 Future `b`
if let Some(b) = &mut self.b {
if let Poll::Ready(()) = b.poll(wake) {
self.b.take();
}
}
if self.a.is_none() && self.b.is_none() {
// 两个 Future都已完成 - 我们可以成功地返回了
Poll::Ready(())
} else {
// 至少还有一个 Future 没有完成任务,因此返回 `Poll::Pending`.
// 当该 Future 再次准备好时,通过调用`wake()`函数来继续执行
Poll::Pending
}
}
}
rust
这些例子展示了在不需要内存对象分配以及深层嵌套回调的情况下,该如何使用 Future 特征去表达异步控制流。 在了解了基础的控制流后,我们再来看看真实的 Future 特征有何不同之处:
trait Future {
type Output;
fn poll(
// 首先值得注意的地方是,`self`的类型从`&mut self`变成了`Pin<&mut Self>`:
self: Pin<&mut Self>,
// 其次将`wake: fn()` 修改为 `cx: &mut Context<'_>`:
cx: &mut Context<'_>,
) -> Poll<Self::Output>;
}
rust
首先这里多了一个 Pin ,现在你只需要知道使用它可以创建一个无法被移动的 Future ,因为无法被移动,所以它将具有固定的内存地址,意味着我们可以存储它的指针(如果内存地址可能会变动,那存储指针地址将毫无意义!),也意味着可以实现一个自引用数据结构: struct MyFut { a: i32, ptr_to_a: *const i32 }。 而对于 async/await 来说,Pin 是不可或缺的关键特性。
其次,从 wake: fn() 变成了 &mut Context<'_> 。意味着 wake 函数可以携带数据了,Context 类型也会通过提供一个 Waker 类型的值,就可以用来唤醒特定的的任务。
使用 Waker 来唤醒任务
对于 Future 来说,第一次被 poll 时无法完成任务是很正常的。但它需要确保在未来一旦准备好时,可以通知执行器再次对其进行 poll 进而继续往下执行,该通知就是通过 Waker 类型完成的。
Waker 提供了一个 wake() 方法可以用于告诉执行器:相关的任务可以被唤醒了,此时执行器就可以对相应的 Future 再次进行 poll 操作。
构建一个定时器
下面一起来实现一个简单的定时器 Future 。为了让例子尽量简单,当计时器创建时,我们会启动一个线程接着让该线程进入睡眠,等睡眠结束后再通知给 Future。
由于新建线程在睡眠结束后会需要将状态同步给定时器 Future,由于是多线程环境,所以需要使用 Arc<Mutex<T>> 来作为一个共享状态,用于在新线程和 Future 定时器间共享。
use std::{
future::Future,
pin::Pin,
sync::{Arc, Mutex},
task::{Context, Poll, Waker},
thread,
time::Duration,
};
/// 在Future和等待的线程间共享状态
struct SharedState {
/// 定时(睡眠)是否结束
completed: bool,
/// 当睡眠结束后,线程可以用`waker`通知`TimerFuture`来唤醒任务
waker: Option<Waker>,
}
pub struct TimerFuture {
shared_state: Arc<Mutex<SharedState>>,
}
impl Future for TimerFuture {
type Output = ();
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
// 通过检查共享状态,来确定定时器是否已经完成
let mut shared_state = self.shared_state.lock().unwrap();
if shared_state.completed {
Poll::Ready(())
} else {
// 设置`waker`,这样新线程在睡眠(计时)结束后可以唤醒当前的任务,接着再次对`Future`进行`poll`操作,
//
// 下面的`clone`每次被`poll`时都会发生一次,实际上,应该是只`clone`一次更加合理。
// 选择每次都`clone`的原因是: `TimerFuture`可以在执行器的不同任务间移动,如果只克隆一次,
// 那么获取到的`waker`可能已经被篡改并指向了其它任务,最终导致执行器运行了错误的任务
shared_state.waker = Some(cx.waker().clone());
Poll::Pending
}
}
}
rust
代码很简单,只要新线程设置了 shared_state.completed = true ,那任务就能顺利结束。如果没有设置,会为当前的任务克隆一份 Waker ,这样新线程就可以使用它来唤醒当前的任务。
最后,再来创建一个 API 用于构建定时器和启动计时线程:
impl TimerFuture {
/// 创建一个新的`TimerFuture`,在指定的时间结束后,该`Future`可以完成
pub fn new(duration: Duration) -> Self {
let shared_state = Arc::new(Mutex::new(SharedState {
completed: false,
waker: None,
}));
// 创建新线程
let thread_shared_state = shared_state.clone();
thread::spawn(move || {
// 睡眠指定时间实现计时功能
thread::sleep(duration);
let mut shared_state = thread_shared_state.lock().unwrap();
// 通知执行器定时器已经完成,可以继续`poll`对应的`Future`了
shared_state.completed = true;
if let Some(waker) = shared_state.waker.take() {
waker.wake()
}
});
TimerFuture { shared_state }
}
}
rust
至此,一个简单的定时器 Future 就已创建成功,我们需要创建一个执行器,才能让程序动起来。
执行器 Executor
Rust 的 Future 是惰性的,其中一个推动它的方式就是在 async 函数中使用 .await 来调用另一个 async 函数,但是这个只能解决 async 内部的问题,在最外层的 async 函数,则需要执行器 executor 来进行推动了。
执行器会管理一批 Future (最外层的 async 函数),然后通过不停地 poll 推动它们直到完成。 最开始,执行器会先 poll 一次 Future ,后面就不会主动去 poll 了,而是等待 Future 通过调用 wake 函数来通知它可以继续,它才会继续去 poll 。这种 wake 通知然后 poll 的方式会不断重复,直到 Future 完成。
构建执行器
编辑Cargo.toml,导入依赖:
[dependencies]
futures = "0.3"
toml
现在在 src/main.rs 中来创建程序的主体内容,开始之前,先引入所需的包:
use {
futures::{
future::{BoxFuture, FutureExt},
task::{waker_ref, ArcWake},
},
std::{
future::Future,
sync::mpsc::{sync_channel, Receiver, SyncSender},
sync::{Arc, Mutex},
task::{Context, Poll},
time::Duration,
},
// 引入之前实现的定时器模块
timer_future::TimerFuture,
};
rust
执行器需要从一个消息通道(channel)中拉取事件,然后运行它们。当一个任务准备好后(可以继续执行),它会将自己放入消息通道中,然后等待执行器 poll:
/// 任务执行器,负责从通道中接收任务然后执行
struct Executor {
ready_queue: Receiver<Arc<Task>>,
}
/// `Spawner`负责创建新的`Future`然后将它发送到任务通道中
#[derive(Clone)]
struct Spawner {
task_sender: SyncSender<Arc<Task>>,
}
/// 一个Future,它可以调度自己(将自己放入任务通道中),然后等待执行器去`poll`
struct Task {
/// 进行中的Future,在未来的某个时间点会被完成
///
/// 按理来说`Mutex`在这里是多余的,因为我们只有一个线程来执行任务。但是由于
/// Rust并不聪明,它无法知道`Future`只会在一个线程内被修改,并不会被跨线程修改。因此
/// 我们需要使用`Mutex`来满足这个笨笨的编译器对线程安全的执着。
///
/// 如果是生产级的执行器实现,不会使用`Mutex`,因为会带来性能上的开销,取而代之的是使用`UnsafeCell`
future: Mutex<Option<BoxFuture<'static, ()>>>,
/// 可以将该任务自身放回到任务通道中,等待执行器的poll
task_sender: SyncSender<Arc<Task>>,
}
fn new_executor_and_spawner() -> (Executor, Spawner) {
// 任务通道允许的最大缓冲数(任务队列的最大长度)
// 当前的实现仅仅是为了简单,在实际的执行中,并不会这么使用
const MAX_QUEUED_TASKS: usize = 10_000;
let (task_sender, ready_queue) = sync_channel(MAX_QUEUED_TASKS);
(Executor { ready_queue }, Spawner { task_sender })
}
rust
下面再来添加一个方法用于生成 Future , 然后将它放入任务通道中:
impl Spawner {
fn spawn(&self, future: impl Future<Output = ()> + 'static + Send) {
let future = future.boxed();
let task = Arc::new(Task {
future: Mutex::new(Some(future)),
task_sender: self.task_sender.clone(),
});
self.task_sender.send(task).expect("任务队列已满");
}
}
rust
在执行器 poll 一个 Future 之前,首先需要调用 wake 方法进行唤醒,然后再由 Waker 负责调度该任务并将其放入任务通道中。创建 Waker 的最简单的方式就是实现 ArcWake 特征,先来为我们的任务实现 ArcWake 特征,这样它们就能被转变成 Waker 然后被唤醒:
impl ArcWake for Task {
fn wake_by_ref(arc_self: &Arc<Self>) {
// 通过发送任务到任务管道的方式来实现`wake`,这样`wake`后,任务就能被执行器`poll`
let cloned = arc_self.clone();
arc_self
.task_sender
.send(cloned)
.expect("任务队列已满");
}
}
rust
当任务实现了 ArcWake 特征后,它就变成了 Waker ,在调用 wake() 对其唤醒后会将任务复制一份所有权(Arc),然后将其发送到任务通道中。最后我们的执行器将从通道中获取任务,然后进行 poll 执行:
impl Executor {
fn run(&self) {
while let Ok(task) = self.ready_queue.recv() {
// 获取一个future,若它还没有完成(仍然是Some,不是None),则对它进行一次poll并尝试完成它
let mut future_slot = task.future.lock().unwrap();
if let Some(mut future) = future_slot.take() {
// 基于任务自身创建一个 `LocalWaker`
let waker = waker_ref(&task);
let context = &mut Context::from_waker(&*waker);
// `BoxFuture<T>`是`Pin<Box<dyn Future<Output = T> + Send + 'static>>`的类型别名
// 通过调用`as_mut`方法,可以将上面的类型转换成`Pin<&mut dyn Future + Send + 'static>`
if future.as_mut().poll(context).is_pending() {
// Future还没执行完,因此将它放回任务中,等待下次被poll
*future_slot = Some(future);
}
}
}
}
}
rust
恭喜!我们终于拥有了自己的执行器,下面再来写一段代码使用该执行器去运行之前的定时器 Future:
fn main() {
let (executor, spawner) = new_executor_and_spawner();
// 生成一个任务
spawner.spawn(async {
println!("howdy!");
// 创建定时器Future,并等待它完成
TimerFuture::new(Duration::new(2, 0)).await;
println!("done!");
});
// drop掉任务,这样执行器就知道任务已经完成,不会再有新的任务进来
drop(spawner);
// 运行执行器直到任务队列为空
// 任务运行后,会先打印`howdy!`, 暂停2秒,接着打印 `done!`
executor.run();
}
rust
Pin 和 Unpin
在 Rust 中,所有的类型可以分为两类:
- 类型的值可以在内存中安全地被移动,例如数值、字符串、布尔值、结构体、枚举,总之你能想到的几乎所有类型都可以落入到此范畴内
- 自引用类型,大魔王来了,大家快跑,在之前章节我们已经见识过它的厉害
下面就是一个自引用类型:
struct SelfRef {
value: String,
pointer_to_value: *mut String,
}
rust
在上面的结构体中,pointer_to_value 是一个裸指针,指向第一个字段 value 持有的字符串 String。现在考虑一个情况, 若 String 被移动了怎么办?
此时一个致命的问题就出现了:新的字符串的内存地址变了,而 pointer_to_value 依然指向之前的地址,一个重大 bug 就出现了!
在这里,Pin 闪亮登场,它可以防止一个类型在内存中被移动。
为何需要 Pin
其实 Pin 还有一个小伙伴 UnPin ,与前者相反,后者表示类型可以在内存中安全地移动。在深入之前,我们先来回忆下 async / .await 是如何工作的:
let fut_one = /* ... */; // Future 1
let fut_two = /* ... */; // Future 2
async move {
fut_one.await;
fut_two.await;
}
rust
在底层,async 会创建一个实现了 Future 的匿名类型,并提供了一个 poll 方法:
// `async { ... }`语句块创建的 `Future` 类型
struct AsyncFuture {
fut_one: FutOne,
fut_two: FutTwo,
state: State,
}
// `async` 语句块可能处于的状态
enum State {
AwaitingFutOne,
AwaitingFutTwo,
Done,
}
impl Future for AsyncFuture {
type Output = ();
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> {
loop {
match self.state {
State::AwaitingFutOne => match self.fut_one.poll(..) {
Poll::Ready(()) => self.state = State::AwaitingFutTwo,
Poll::Pending => return Poll::Pending,
}
State::AwaitingFutTwo => match self.fut_two.poll(..) {
Poll::Ready(()) => self.state = State::Done,
Poll::Pending => return Poll::Pending,
}
State::Done => return Poll::Ready(()),
}
}
}
}
rust
当 poll 第一次被调用时,它会去查询 fut_one 的状态,若 fut_one 无法完成,则 poll 方法会返回。未来对 poll 的调用将从上一次调用结束的地方开始。该过程会一直持续,直到 Future 完成为止。
然而,如果我们的 async 语句块中使用了引用类型,会发生什么?例如下面例子:
async {
let mut x = [0; 128];
let read_into_buf_fut = read_into_buf(&mut x);
read_into_buf_fut.await;
println!("{:?}", x);
}
rust
这段代码会编译成下面的形式:
struct ReadIntoBuf<'a> {
buf: &'a mut [u8], // 指向下面的`x`字段
}
struct AsyncFuture {
x: [u8; 128],
read_into_buf_fut: ReadIntoBuf<'what_lifetime?>,
}
rust
这里,ReadIntoBuf 拥有一个引用字段,指向了结构体的另一个字段 x ,一旦 AsyncFuture 被移动,那 x 的地址也将随之变化,此时对 x 的引用就变成了不合法的,也就是 read_into_buf_fut.buf 会变为不合法的。
若能将 Future 在内存中固定到一个位置,就可以避免这种问题的发生,也就可以安全的创建上面这种引用类型。
Unpin
事实上,绝大多数类型都不在意是否被移动(开篇提到的第一种类型),因此它们都自动实现了 Unpin 特征。
Pin 不按套路出牌,它是一个结构体:
pub struct Pin<P> {
pointer: P,
}
rust
它包裹一个指针,并且能确保该指针指向的数据不会被移动,例如 Pin<&mut T> , Pin<&T> , Pin<Box<T>> ,都能确保 T 不会被移动。
而 Unpin 才是一个特征,它表明一个类型可以随意被移动,但是可以被 Pin 住的值实现的特征是 !Unpin,!Unpin 说明类型没有实现 Unpin 特征,那自然就可以被 Pin 了。
对实现了 Unpin 特征的类型使用 Pin,不会产生任何效果,该值一样可以被移动。
深入理解 Pin
对于上面的问题,我们可以简单的归结为如何在 Rust 中处理自引用类型(果然,只要是难点,都和自引用脱离不了关系),下面用一个稍微简单点的例子来理解下 Pin :
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
}
impl Test {
fn new(txt: &str) -> Self {
Test {
a: String::from(txt),
b: std::ptr::null(),
}
}
fn init(&mut self) {
let self_ref: *const String = &self.a;
self.b = self_ref;
}
fn a(&self) -> &str {
&self.a
}
fn b(&self) -> &String {
assert!(!self.b.is_null(), "Test::b called without Test::init being called first");
unsafe { &*(self.b) }
}
}
rust
Test 提供了方法用于获取字段 a 和 b 的值的引用。这里 b 是 a 的一个引用,但是我们并没有使用引用类型而是用了裸指针,原因是:Rust 的借用规则不允许我们这样用,因为不符合生命周期的要求。 此时的 Test 就是一个自引用结构体。
如果不移动任何值,那么上面的例子将没有任何问题,例如:
fn main() {
let mut test1 = Test::new("test1");
test1.init();
let mut test2 = Test::new("test2");
test2.init();
println!("a: {}, b: {}", test1.a(), test1.b());
println!("a: {}, b: {}", test2.a(), test2.b());
}
rust
输出非常正常:
a: test1, b: test1 a: test2, b: test2log
既然移动数据会导致指针不合法,那我们就移动下数据试试,将 test1 和 test2 进行下交换:
fn main() {
let mut test1 = Test::new("test1");
test1.init();
let mut test2 = Test::new("test2");
test2.init();
println!("a: {}, b: {}", test1.a(), test1.b());
std::mem::swap(&mut test1, &mut test2);
println!("a: {}, b: {}", test2.a(), test2.b());
}
rust
实际运行后,却产生了下面的输出:
a: test1, b: test1 a: test1, b: test2log
原因是 test2.b 指针依然指向了旧的地址,而该地址对应的值现在在 test1 里,最终会打印出意料之外的值。
可以借助下图理解:
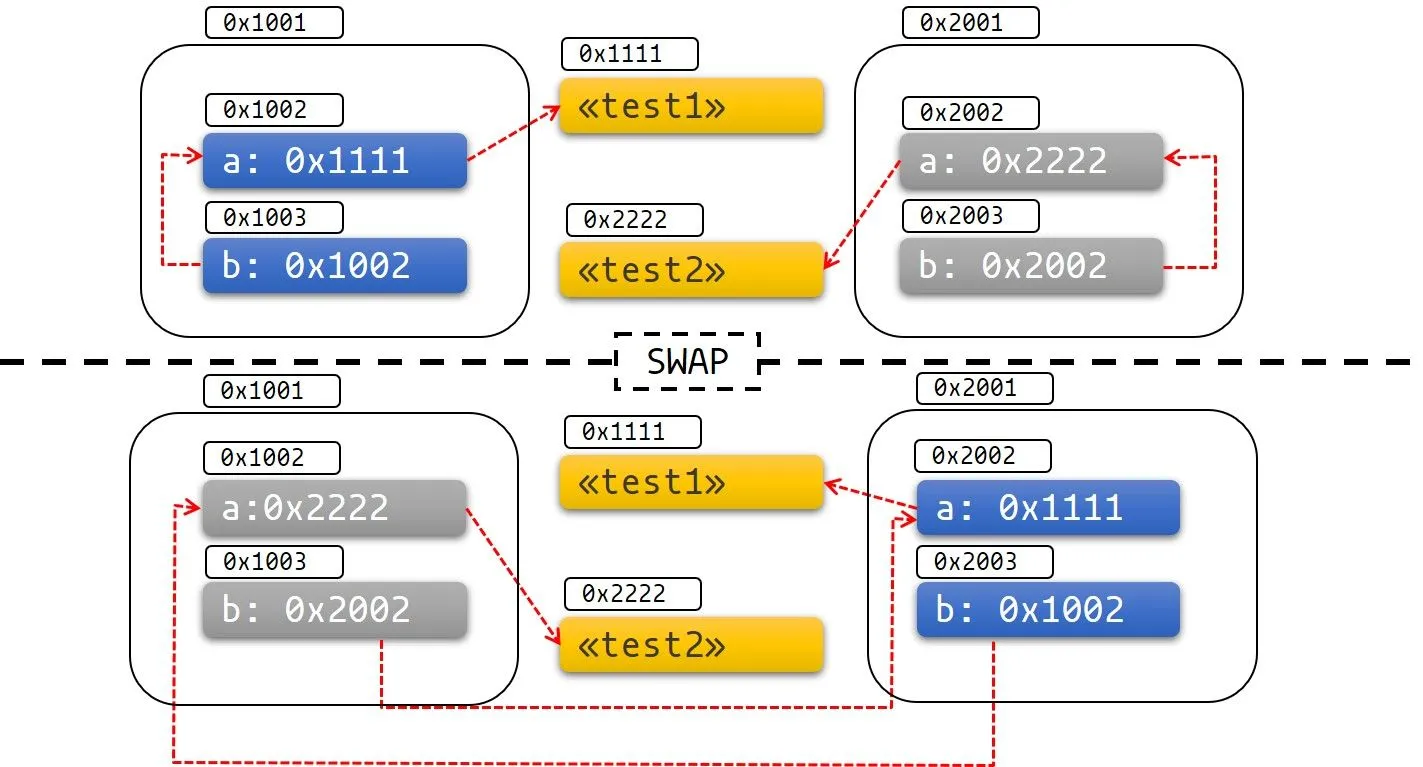
Pin 在实践中的运用
当一个值被移动的时候,通常是将一个值的所有字节复制到另外一个内存地址去,但在 rust 中,唯一的区别就是移动时会带走所有权。所以使用地址来引用一个值是非常不稳定的,编译器被允许在不运行一段代码来提醒某个值被移动的情况下,将一个值移动到一个新的内存地址去,尽管编译器不会在没有显示声明移动的情况下来移动某一个值,但是一个值可能存在多种情况来导致它被移动:
#![allow(unused)]
fn main() {
#[derive(Default)]
struct AddrTracker(Option<usize>);
impl AddrTracker {
// If we haven't checked the addr of self yet, store the current
// address. If we have, confirm that the current address is the same
// as it was last time, or else panic.
fn check_for_move(&mut self) {
let current_addr = self as *mut Self as usize;
match self.0 {
None => self.0 = Some(current_addr),
Some(prev_addr) => assert_eq!(prev_addr, current_addr),
}
}
}
// Create a tracker and store the initial address
let mut tracker = AddrTracker::default();
tracker.check_for_move();
// Here we shadow the variable. This carries a semantic move, and may therefore also
// come with a mechanical memory *move*
let mut tracker = tracker;
// May panic!
tracker.check_for_move();
}
rust
即使是一次简单的所有权转移,也会导致内存地址被移动。即使是使用了 Box<T> 和 &mut T,它里面的值也同样可以被编译器随时移动。
Pin 做了什么?Pin 实际上并没有真正从底层实现内存地址的固定,它只是才编译器层面对开发者进行限制,如果你使用 unsafe,你仍然可以将值的内存地址进行修改:
将值固定到栈上
回到之前的例子,我们可以用 Pin 来解决指针指向的数据被移动的问题:
use std::pin::Pin;
use std::marker::PhantomPinned;
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
_marker: PhantomPinned,
}
impl Test {
fn new(txt: &str) -> Self {
Test {
a: String::from(txt),
b: std::ptr::null(),
_marker: PhantomPinned, // 这个标记可以让我们的类型自动实现特征`!Unpin`
}
}
fn init(self: Pin<&mut Self>) {
let self_ptr: *const String = &self.a;
let this = unsafe { self.get_unchecked_mut() };
this.b = self_ptr;
}
fn a(self: Pin<&Self>) -> &str {
&self.get_ref().a
}
fn b(self: Pin<&Self>) -> &String {
assert!(!self.b.is_null(), "Test::b called without Test::init being called first");
unsafe { &*(self.b) }
}
}
rust
上面代码中,我们使用了一个标记类型 PhantomPinned 将自定义结构体 Test 变成了 !Unpin (编译器会自动帮我们实现),因此该结构体无法再被移动。
一旦类型实现了 !Unpin ,那将它的值固定到栈(stack)上就是不安全的行为,因此在代码中我们使用了 unsafe 语句块来进行处理,你也可以使用 pin_utils 来避免 unsafe 的使用。
此时,再去尝试移动被固定的值,就会导致编译错误:
pub fn main() {
// 此时的`test1`可以被安全的移动
let mut test1 = Test::new("test1");
// 新的`test1`由于使用了`Pin`,因此无法再被移动,这里的声明会将之前的`test1`遮蔽掉(shadow)
let mut test1 = unsafe { Pin::new_unchecked(&mut test1) };
Test::init(test1.as_mut());
let mut test2 = Test::new("test2");
let mut test2 = unsafe { Pin::new_unchecked(&mut test2) };
Test::init(test2.as_mut());
println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref()));
std::mem::swap(test1.get_mut(), test2.get_mut());
println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref()));
}
rust
在编译期就完成了,因此没有额外的性能开销:
error[E0277]: `PhantomPinned` cannot be unpinned --> src/main.rs:47:43 | 47 | std::mem::swap(test1.get_mut(), test2.get_mut()); | ^^^^^^^ within `Test`, the trait `Unpin` is not implemented for `PhantomPinned`log
将值固定到堆上
将一个 !Unpin 类型的值固定到堆上,会给予该值一个稳定的内存地址,它指向的堆中的值在 Pin 后是无法被移动的。而且与固定在栈上不同,我们知道堆上的值在整个生命周期内都会被稳稳地固定住。
use std::pin::Pin;
use std::marker::PhantomPinned;
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
_marker: PhantomPinned,
}
impl Test {
fn new(txt: &str) -> Pin<Box<Self>> {
let t = Test {
a: String::from(txt),
b: std::ptr::null(),
_marker: PhantomPinned,
};
let mut boxed = Box::pin(t);
let self_ptr: *const String = &boxed.as_ref().a;
unsafe { boxed.as_mut().get_unchecked_mut().b = self_ptr };
boxed
}
fn a(self: Pin<&Self>) -> &str {
&self.get_ref().a
}
fn b(self: Pin<&Self>) -> &String {
unsafe { &*(self.b) }
}
}
pub fn main() {
let test1 = Test::new("test1");
let test2 = Test::new("test2");
println!("a: {}, b: {}",test1.as_ref().a(), test1.as_ref().b());
println!("a: {}, b: {}",test2.as_ref().a(), test2.as_ref().b());
}
rust
async/await 和 Stream 流处理
async/.await 是 Rust 语法的一部分,它在遇到阻塞操作时( 例如 IO )会让出当前线程的所有权而不是阻塞当前线程,这样就允许当前线程继续去执行其它代码,最终实现并发。
有两种方式可以使用 async: async fn 用于声明函数,async { ... } 用于声明语句块,它们会返回一个实现 Future 特征的值:
// `foo()`返回一个`Future<Output = u8>`,
// 当调用`foo().await`时,该`Future`将被运行,当调用结束后我们将获取到一个`u8`值
async fn foo() -> u8 { 5 }
fn bar() -> impl Future<Output = u8> {
// 下面的`async`语句块返回`Future<Output = u8>`
async {
let x: u8 = foo().await;
x + 5
}
}
rust
async 是懒惰的,直到被执行器 poll 或者 .await 后才会开始运行,其中后者是最常用的运行 Future 的方法。 当 .await 被调用时,它会尝试运行 Future 直到完成,但是若该 Future 进入阻塞,那就会让出当前线程的控制权。当 Future 后面准备再一次被运行时(例如从 socket 中读取到了数据),执行器会得到通知,并再次运行该 Future ,如此循环,直到完成。
async 的生命周期
async fn 函数如果拥有引用类型的参数,那它返回的 Future 的生命周期就会被这些参数的生命周期所限制:
async fn foo(x: &u8) -> u8 { *x }
// 上面的函数跟下面的函数是等价的:
fn foo_expanded<'a>(x: &'a u8) -> impl Future<Output = u8> + 'a {
async move { *x }
}
rust
意味着 async fn 函数返回的 Future 必须满足以下条件: 当 x 依然有效时, 该 Future 就必须继续等待( .await ), 也就是说 x 必须比 Future 活得更久。
在一般情况下,在函数调用后就立即 .await 不会存在任何问题,例如 foo(&x).await。但是,若 Future 被先存起来或发送到另一个任务或者线程,就可能存在问题了:
use std::future::Future;
fn bad() -> impl Future<Output = u8> {
let x = 5;
borrow_x(&x) // ERROR: `x` does not live long enough
}
async fn borrow_x(x: &u8) -> u8 { *x }
rust
以上代码会报错,因为 x 的生命周期只到 bad 函数的结尾。 但是 Future 显然会活得更久:
error[E0597]: `x` does not live long enough --> src/main.rs:4:14 | 4 | borrow_x(&x) // ERROR: `x` does not live long enough | ---------^^- | | | | | borrowed value does not live long enough | argument requires that `x` is borrowed for `'static` 5 | } | - `x` dropped here while still borrowedlog
其中一个常用的解决方法就是将具有引用参数的 async fn 函数转变成一个具有 'static 生命周期的 Future 。 以上解决方法可以通过将参数和对 async fn 的调用放在同一个 async 语句块来实现:
use std::future::Future;
async fn borrow_x(x: &u8) -> u8 { *x }
fn good() -> impl Future<Output = u8> {
async {
let x = 5;
borrow_x(&x).await
}
}
rust
如上所示,通过将参数移动到 async 语句块内, 我们将它的生命周期扩展到 'static, 并跟返回的 Future 保持了一致。
这是原文里这么写的,但是个人感觉生命周期并没有被扩展到 'static,只是 x 的生命周期会在异步块内保持有效,确保了借用在引用结束之前有效。
当.await 遇见多线程执行器
需要注意的是,当使用多线程 Future 执行器( executor )时, Future 可能会在线程间被移动,因此 async 语句块中的变量必须要能在线程间传递。 至于 Future 会在线程间移动的原因是:它内部的任何 .await 都可能导致它被切换到一个新线程上去执行。
由于需要在多线程环境使用,意味着 Rc、 RefCell 、没有实现 Send 的所有权类型、没有实现 Sync 的引用类型,它们都是不安全的,因此无法被使用。
需要注意!实际上它们还是有可能被使用的,只要在 .await 调用期间,它们没有在作用域范围内。
类似的原因,在 .await 时使用普通的锁也不安全,例如 Mutex 。原因是,它可能会导致线程池被锁:当一个任务获取锁 A 后,若它将线程的控制权还给执行器,然后执行器又调度运行另一个任务,该任务也去尝试获取了锁 A ,结果当前线程会直接卡死,最终陷入死锁中。
因此,为了避免这种情况的发生,我们需要使用 futures 包下的锁 futures::lock 来替代 Mutex 完成任务。