1. 字符串
1.1 切片
切片可以让我们引用集合中部分连续的元素序列,而不是引用整个集合。
对于字符串而言,切片就是对String类型中某一部分的引用:
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
rust
对于一个切片,它并没有实际地去拷贝集合中的东西:
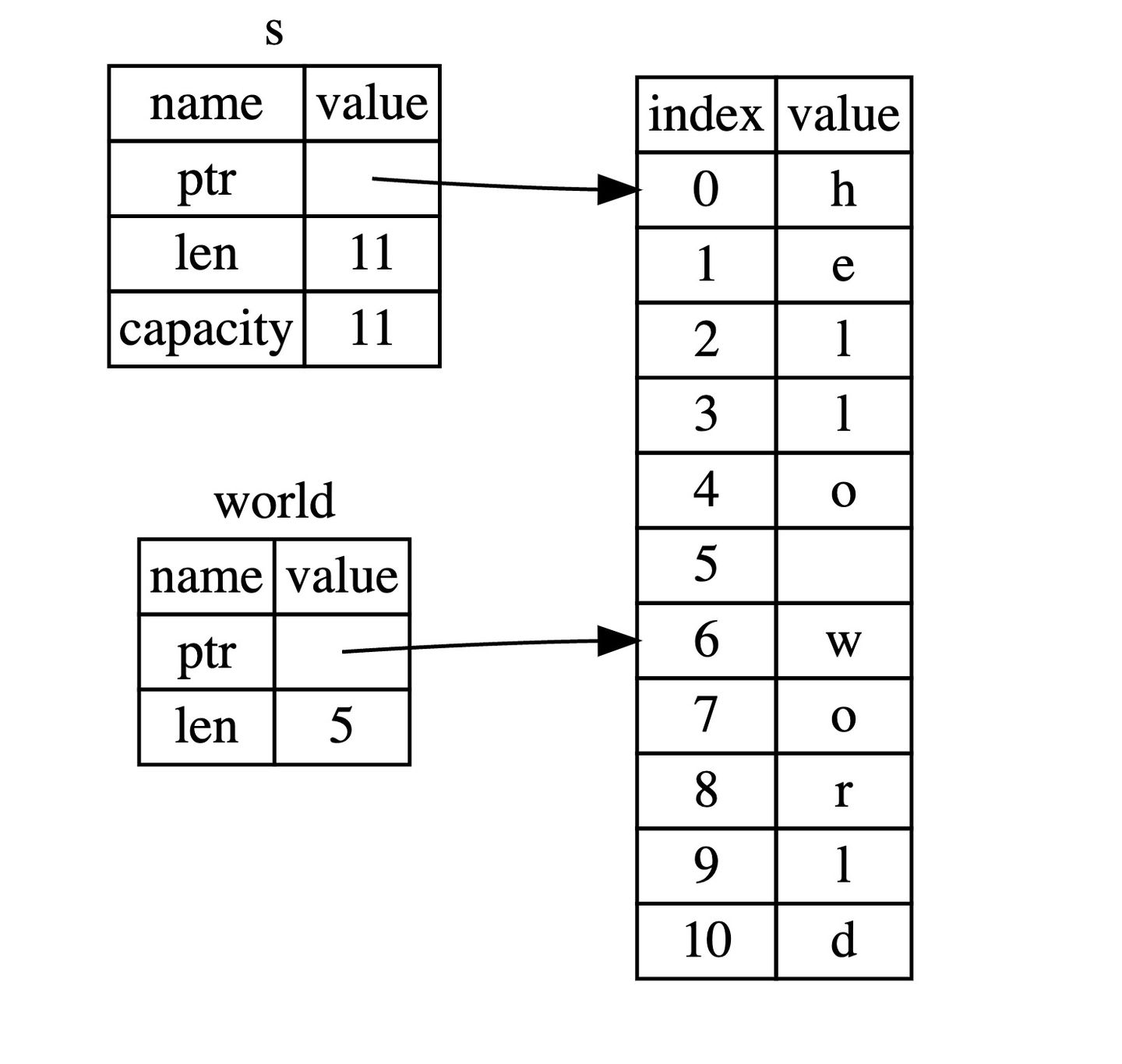
如果想从某个位置到结尾或者开头,可以这样写:
let s = String::from("hello");
// 开头到索引为2的位置
let slice = &s[..2];
// 索引为4到结尾
let slice = &s[4..];
// 甚至全部切片。。
let slice = &s[..];
rust
对字符串使用切片时,如果索引没有落到边界位置,代码则会导致崩溃。
例如汉字在UTF-8中占三个字节,下面的代码会导致崩溃:
let s = "中国人";
// 在这里就报错了,并没有走到后面的打印语句
let a = &s[0..2];
println!("{}",a);
rust
报错信息:
byte index 2 is not a char boundary; it is inside '中' (bytes 0..3) of `中国人` stack backtrace: ...log
1.2 str和String以及&str
str只是类型级别的东西,它只能用来在类型级别上发挥作用,它是动态大小类型,因此str占用的大小在编译时无法确定,只能在 运行时才能确定,所以无法将其存储在变量中:
let s = "hello".to_string();
let b = s[..];
let a = b;
rust
报错:
| 6 | let a = b; | ^ doesn't have a size known at compile-time |log
str代表u8字节的一个数组,而且保证其形成有效的UTF-8,但是不知道其大小,它会被硬编码进可执行文件,也无法被修改。
可以理解为String内容有一个str并且拥有其所有权,而&str只有一个可读引用。
其实这里我当初也没明白,我都用双引号来给字符串了,而且又是UTF-8,长度怎么就不明白呢?
到后面查了很多资料才明白了,首先是因为
str类型的字符串它没有保存长度,而&str保存了长度,具体为什么不保存长度我也不知道,网上也没有搜到相关内容,个人猜测是为了字符串复用?然后我们知道Rust的GC是自动的,变量退出作用域自动被回收,但是回收的前提是你需要知道这个变量在内存的什么位置,以及它的大小,而str类型是没有保存大小的,如果直接放到变量中使用,是无法进行内存回收的,因为不知道其具体大小,例如下面的代码:我们在这里获取了
str的所有权,在函数结束时就需要将其回收,而在这里无法确定str的大小,因此无法进行回收。
1.3 字符串索引
在rust中,使用索引访问字符串的某个字符会导致报错:
let s1 = String::from("hello");
let h = s1[0];
rust
报错:
3 | let h = s1[0]; | ^^^^^ `String` cannot be indexed by `{integer}` | = help: the trait `Index<{integer}>` is not implemented for `String`log
在字符串底层的数据存储格式实际上是一个u8数组,而UTF-8中,每种类型的字符所占的字节都不一样,所以无法使用
索引来取值。
1.4 字符串操作
1.4.1 追加
push(): 追加字符charpush_str():追加字符串字面量
追加要求被修改的字符串必须是可变的,所以对应的变量必须被mut修饰:
fn main() {
let mut s = String::from("Hello ");
s.push_str("rust");
println!("追加字符串 push_str() -> {}", s);
s.push('!');
println!("追加字符 push() -> {}", s);
}
rust
1.4.2 插入
insert():插入单个字符charinsert_str():插入字符串字面量
插入方法同时需要提供插入的索引,并且也需要保证插入位置在字符的边界:
fn main() {
let mut s = String::from("Hello rust!");
s.insert(5, ',');
println!("插入字符 insert() -> {}", s);
s.insert_str(6, " I like");
println!("插入字符串 insert_str() -> {}", s);
}
rust
1.4.3 替换
replace():可同时用在&str和String类型上,会替换掉所有满足的字符串。replacen():可同时用在&str和String类型上,接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。replace_range():只能在String上使用,表示替换一定范围内的字符串。
上面的方法都会返回一个新的字符串,而不是操作原来的字符串。
let string_replace = String::from("I like rust. Learning rust is my favorite!");
// "I like RUST. Learning RUST is my favorite!"
let new_string_replace = string_replace.replace("rust", "RUST");
let string_replace = "I like rust. Learning rust is my favorite!";
// I like RUST. Learning rust is my favorite!
let new_string_replacen = string_replace.replacen("rust", "RUST", 1);
dbg!(new_string_replacen);
let mut string_replace_range = String::from("I like rust!");
// I like Rust!
string_replace_range.replace_range(7..8, "R");
rust
1.4.4 删除
删除相关的方法都只适用于String,并且都会改变原来的字符串。
pop():删除并返回字符串的最后一个字符remove():删除并返回字符串中指定位置的字符,使用时需要保证索引在字符边界的起始位置truncate():删除字符串中从指定位置开始到结尾的全部字符,需要保证索引在字符的结束位置clear():清空字符串,类似于truncate(0)
let mut string_pop = String::from("rust pop 中文");
// '文'
let p1 = string_pop.pop();
let mut string_remove = String::from("测试remove方法");
// 删除第一个汉字
string_remove.remove(0);
// 下面代码会发生错误
// string_remove.remove(1);
// 直接删除第二个汉字
// string_remove.remove(3);
let mut string_truncate = String::from("测试truncate");
// "测"
string_truncate.truncate(3);
rust
1.4.5 连接
使用+连接字符串
可以使用+或者+=连接字符串,要求右边的参数必须为字符串的切片引用类型。+返回的是一个新的字符串,操作时可以不需要mut关键字。
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
// &string_rust会自动解引用为&str
let result = string_append + &string_rust;
let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的
result += "!!!";
// 连接字符串 + -> hello rust!!!!
println!("连接字符串 + -> {}", result);
}
rust
对于以下代码会导致报错:
fn main() {
let s1 = String::from("hello,");
let s2 = String::from("world!");
// 在下句中,s1的所有权被转移走了,因此后面不能再使用s1
let s3 = s1 + &s2;
assert_eq!(s3,"hello,world!");
// 下面的语句如果去掉注释,就会报错
// println!("{}",s1);
}
rust
看起来很难理解,其实换一下就知道了,add的类型定义为:
fn add(self, s: &str) -> String {}
rust
我们换成add来看:
let a = "ss".to_string();
let b = a.add("eee");
// 报错,a已经转移给b
println!("{}", a);
rust
这里我们就可以理解为调用add方法后,变量a返回了它自己。
使用format!连接字符串
format! 这种方式适用于 String 和 &str 。format! 的用法与 print! 的用法类似,详见格式化输出。
fn main() {
let s1 = "hello";
let s2 = String::from("rust");
let s = format!("{} {}!", s1, s2);
// hello rust!
println!("{}", s);
}
rust
1.5 字符串转义
可以通过转义(\)的方式输出 ASCII 和 Unicode 字符。
fn main() {
// 通过 \ + 字符的十六进制表示,转义输出一个字符
let byte_escape = "I'm writing \x52\x75\x73\x74!";
println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape);
// \u 可以输出一个 unicode 字符
let unicode_codepoint = "\u{211D}";
let character_name = "\"DOUBLE-STRUCK CAPITAL R\"";
println!(
"Unicode character {} (U+211D) is called {}",
unicode_codepoint, character_name
);
// 换行了也会保持之前的字符串格式
// 使用\忽略换行符
let long_string = "String literals
can span multiple lines.
The linebreak and indentation here ->\
<- can be escaped too!";
println!("{}", long_string);
}
rust
特殊的转义符:
fn main() {
println!("{}", "hello \\x52\\x75\\x73\\x74");
let raw_str = r"Escapes don't work here: \x3F \u{211D}";
println!("{}", raw_str);
// 如果字符串包含双引号,可以在开头和结尾加 #
let quotes = r#"And then I said: "There is no escape!""#;
println!("{}", quotes);
// 如果还是有歧义,可以继续增加,没有限制
let longer_delimiter = r###"A string with "# in it. And even "##!"###;
println!("{}", longer_delimiter);
}
rust
1.6 操作 UTF-8 字符串
以 Unicode 字符的方式遍历字符串:
for c in "中国人".chars() {
println!("{}", c);
}
rust
输出:
中 国 人log
以字节的方式遍历:
for b in "中国人".bytes() {
println!("{}", b);
}
rust
输出:
228 184 173 229 155 189 228 186 186log
如果需要精准的从UTF-8字符串中获取子串,可能需要借助其它的标准库,例如:utf8_slice
2. 元组
元组是由多种类型组合到一起形成的,因此它是复合类型,元组的长度是固定的,元组中元素的顺序也是固定的:
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}
rust
获取元组的值:
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {}", y);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}
rust
3. 结构体
结构体由struct定义,它由不同的字段组成:
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
rust
该结构体名称是 User,拥有 4 个字段,且每个字段都有对应的字段名及类型声明,例如 username 代表了用户名,是一个可变的 String 类型。
创建一个结构体实例:
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
rust
有几点值得注意:
- 初始化实例时,每个字段都需要进行初始化
- 初始化时的字段顺序不需要和结构体定义时的顺序一致
通过.即可访问/操作结构体字段:
let mut user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
rust
只有将结构体声明为可变的才能修改其字段,rust不允许结构体部分字段可变。
rust支持跟TypeScript一样的简化操作:
fn build_user(email: String, username: String) -> User {
User {
// email: email,
email,
// username: username
username,
active: true,
sign_in_count: 1,
}
}
rust
也可以类似与ts解构一个对象(注意这里是两个点,ts是三个点):
let user2 = User {
email: String::from("another@example.com"),
..user1
};
rust
当结构体部分字段所有权被转移时,该结构体将不可用,但是其它字段仍然可用:
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
println!("{}", user1.active);
// 下面这行会报错
println!("{:?}", user1);
rust
3.1 内存体的结构排序
如下的结构体:
#[derive(Debug)]
struct File {
name: String,
data: Vec<u8>,
}
rust
在内存中的结构为:
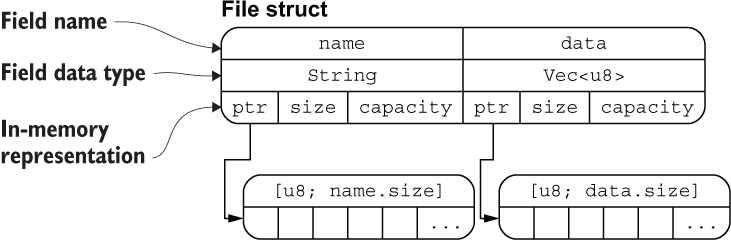
从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权,通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
3.2 元组结构体
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得很像元组,因此被称为元组结构体,例如:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
rust
元组结构体在你希望有一个整体名称,但是又不关心里面字段的名称时将非常有用。例如上面的 Point 元组结构体,众所周知 3D 点是 (x, y, z) 形式的坐标点,因此我们无需再为内部的字段逐一命名为:x, y, z。
注意在解构时需要加上类型:
let black = Color(0, 0, 0);
// error
let (r, g, b) = black;
let Color(r, g, b) = black;
rust
4. 枚举
枚举(enum 或 enumeration)允许你通过列举可能的成员来定义一个枚举类型,例如扑克牌花色:
enum PokerSuit {
Clubs,
Spades,
Diamonds,
Hearts,
}
rust
使用枚举值:
let heart = PokerSuit::Hearts;
let diamond = PokerSuit::Diamonds;
rust
在函数中使用:
fn main() {
let heart = PokerSuit::Hearts;
let diamond = PokerSuit::Diamonds;
print_suit(heart);
print_suit(diamond);
}
fn print_suit(card: PokerSuit) {
// 需要在定义 enum PokerSuit 的上面添加上 #[derive(Debug)],否则会报 card 没有实现 Debug
println!("{:?}",card);
}
rust
枚举也可以提供固定的值,但是只能使用isize类型的整型,例如:
enum RankScore {
FIRST = 100,
SECOND = 90,
THIRD = 80,
// FOURTH会以上面的基础 + 1
FOURTH
}
fn main() {
// 使用时必须使用as强转为isize或者其它整型
// THIRD = 80, FOURTH = 81
println!("THIRD = {}, FOURTH = {}", RankScore::THIRD as isize, RankScore::FOURTH as isize)
}
rust
如果没有指定明确的值,则以0开始递增。
在rust中可以给枚举带上类型,例如这样:
enum PokerCard {
Clubs(u8),
Spades(u8),
Diamonds(u8),
Hearts(u8),
}
fn main() {
let c1 = PokerCard::Spades(5);
let c2 = PokerCard::Diamonds(13);
}
rust
例如标准库中的例子:
struct Ipv4Addr {
// --snip--
}
struct Ipv6Addr {
// --snip--
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
rust
在实际使用中,每种枚举字段的类型可以不一样:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let m1 = Message::Quit;
let m2 = Message::Move{x:1,y:1};
let m3 = Message::ChangeColor(255,255,0);
}
rust
4.1 访问枚举值
如果枚举值自带了类型,访问时则需要使用匹配模式来访问:
fn main() {
let msg = Message::Move{x: 1, y: 2};
if let Message::Move{x: a, y: b} = msg {
// use data from Message::Move
assert_eq!(a, b);
} else {
// not Message::Move
}
}
rust
在这里无法对msg变量被视作了Message类型,即使创建时使用了Message::Move。如果尝试将msg使用as强转为Message::Move,则会报错:
| 11 | let Message::Move { x, y } = msg as Message::Move; | ^^^^^^^^^^^^^ | | | not a type | help: try using the variant's enum: `crate::Message`log
4.2 空值
在Java或其它语言中,null表示一个空值,它可以被赋给任何对象,如果尝试访问一个空对象的任何属性或方法,则会造成空指针异常导致程序崩溃。
因此rust舍弃了空值,而改为使用Option枚举变量来表述这种结果:
enum Option<T> {
Some(T),
None,
}
rust
其中 T 是泛型参数,Some(T)表示该枚举成员的数据类型是 T,换句话说,Some 可以包含任何类型的数据。
Option是被默认导入的(被包含在了rust标准库prelude中),即不需要显式导入即可使用:
let some_number = Some(5);
let some_string = Some("a string");
let absent_number: Option<i32> = None;
rust
5. 数组
在 Rust 中,最常用的数组有两种,第一种是速度很快但是长度固定的 array,第二种是可动态增长的但是有性能损耗的 Vector。
5.1 创建数组
创建一个数组:
fn main() {
let a = [1, 2, 3, 4, 5];
// 效果同上
let a: [i32; 5] = [1, 2, 3, 4, 5];
// 初始化某个值出现N次的数组, [类型; 长度],只有类型支持Copy的才能使用
// 长度必须在编译时就已知,不能为动态值
let a = [3; 5];
}
rust
5.2 访问数组
数组访问和其它语言一样,使用下标索引访问:
fn main() {
let a = [9, 8, 7, 6, 5];
let first = a[0]; // 获取a数组第一个元素
let second = a[1]; // 获取第二个元素
// 获取数组长度
let len = a.len();
}
rust
如果出现数组越界异常,则会导致程序崩溃,崩溃是在运行时崩溃,而不是编译期。
5.3 数组切片
数组切片允许你引用集合中的部分连续片段,而不是整个集合:
let a: [i32; 5] = [1, 2, 3, 4, 5];
let slice: &[i32] = &a[1..3];
assert_eq!(slice, &[2, 3]);
rust
- 切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
- 创建切片的代价非常小,因为切片只是针对底层数组的一个引用
- 切片类型[T]拥有不固定的大小,而切片引用类型&[T]则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此&[T]更有用,&str字符串切片也同理