1. 下载安装
直接下载安装包即可,下载完成后不需要配置环境变量之类的,SVN也不需要你去命令行里去敲哪些什么指令,它自己有很丰富的图形客户端,这点是比GIT好一点点的。
直接对着任意地方右键,如果出现TortoiseSVN的选项,就说明安装成功了(对着桌面按是没有的,需要进随便一个文件夹)。
2. 创建仓库
SVN不支持离线操作,也就是说你想要创建一个仓库,你必须先去服务器支棱一个起来,这里我们直接用码云(工作台 - Gitee.com)就好了。
随便创建一个项目,点击管理 -> 功能设置 -> 启用SVN访问。
之后克隆项目,记得要选SVN的协议:
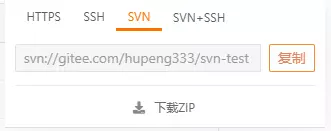
之后进入任意文件夹,鼠标右键,点击Checkout,之后会弹出来这个:
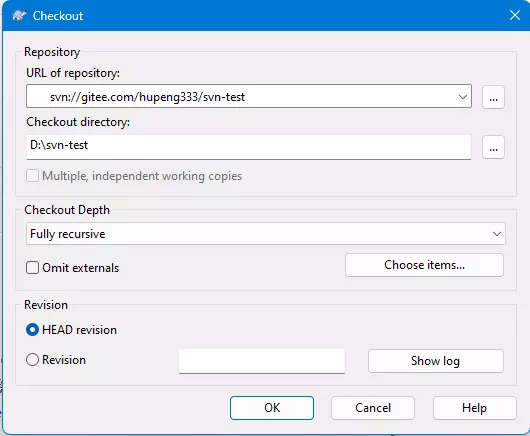
第一个表单就是我们的仓库地址,第二个就是我们要将项目拉到的地方,第三Checkout Depth就是你克隆的深度,你可以选择全部复制(Fully recursive),也可以选择部分,一般配合下面的Choose items按钮使用。
Omit externals表示忽略外部设备,目前不是很清楚有什么用。
最后一个框(Revision)就是版本信息选择了,你可以直接选择最新分支(HEAD revision),也可以通过Show log选择历史分支来进行克隆。
选好后点击OK进行克隆。
3. 提交修改
我们在本地进行任意修改,修改完后在任意子目录或者根目录鼠标右键,在TortoiseSVN选项下找到Commit选项,点开会出现这个:
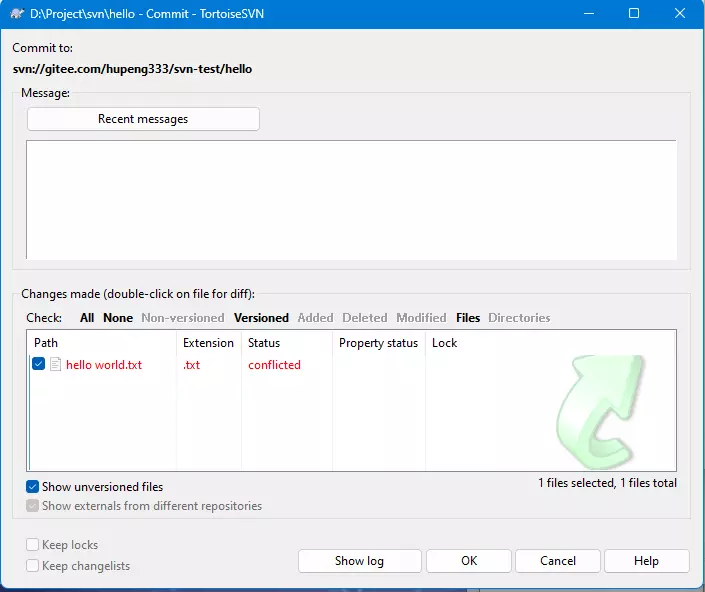
最上面的Message就是提交信息,没有什么好说的。
下面那个框就是选择你需要提交的文件。
注意:SVN的Commit会直接提交到服务器,它不是跟Git一样本地提交!!!千万不要乱提交。
下面有个按钮,分别的作用是:
- Show unversioned files:显示被排除的文件(不受版本控制的文件)
其它的暂时用不上,我们选好后,直接提交,然后再去码云上看,就可以看到提交结果了。
4. 解决冲突
这里我们先在码云上修改一下,然后也在本地修改同样的文件,然后在本地提交:
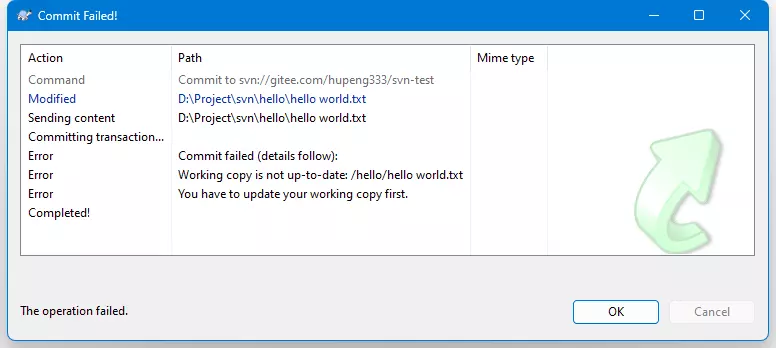
提交失败了,可以发现它让我们去更新:
You have to update your working copy firsttext
那我们就更新,直接项目目录下右键,点击Update,结果又报错了:
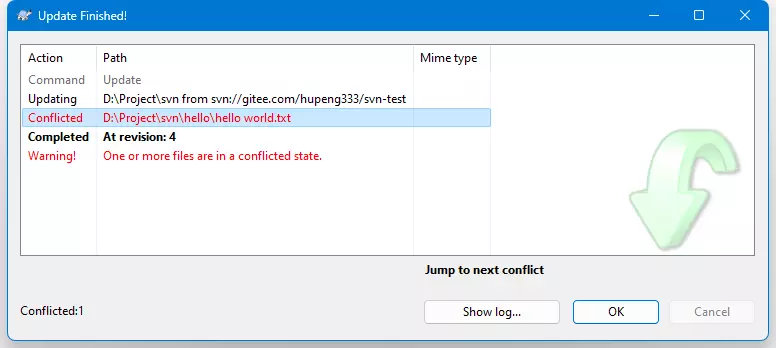
可以发现是因为出现了文件冲突,和Git一样,我们需要先解决冲突后再提交。
这里是我本地的文件内容:
hello world hello world hello world hello world 12312 312 3 12 3 12 3 12 3 hello worldtext
这是服务器的:
hello world 12312 312 3 12 3 12 3 12 3 12312 312 3 12 3 12 3 12 3 123312312text
这是发生冲突后的文件:
hello world hello world hello world hello world <<<<<<< .mine hello world ||||||| .r3 12312 312 3 12 3 12 3 12 3======= 12312 312 3 12 3 12 3 12 3 123312312>>>>>>> .r4text
这特么谁看得懂,别急,还记得之前我说过SVN有丰富的图形客户端吗?这里就还真有解决冲突用的玩意:
打开后就非常直观了,这里就不放图了,修改完后点击左上角的Save保存,这时它会问你冲突是否已经解决完毕了,如果选择解决完了(Mark as resolved),就可以直接提交了。当然如果又冲突了,就又需要重复上述过程。
5. 代码暂存
待补坑。
1. 为什么要用Netty
Netty是一个基于Java NIO封装的高性能网络通信框架。它主要有以下优势:
- Netty提供了比NIO更简单的API
- 很容易地实现Reactor模型
- Netty在NIO的基础上做出了很多优化
- 内存池
- 零拷贝
- Netty内置了多种通信协议
用官方的总结就是:Netty 成功地找到了一种在不妥协可维护性和性能的情况下实现易于开发,性能,稳定性和灵活性的方法。
2. Netty零拷贝
Netty零拷贝主要在五个方面:
- Netty默认情况下使用直接内存,避免了从JVM堆内存拷贝到直接内存这一次拷贝,而是直接从直接使用直接内存进行Socket读写
- Netty的文件传输调用了
FileRegion包装的transferTo方法,可以直接将文件从缓冲区发送到目标Channel - Netty提供了
CompositeByteBuf类,可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了多个ByteBuf的拷贝。 - 通过
ByteBuf.wrap方法,可以将byte[]数组、ByteBuffer包装成一个ByteBuf,从而避免了拷贝 ByteBuf支持slice操作,可以将ByteBuf分解为多个共享同一存储区域的ByteBuf,避免了内存的拷贝
3. Netty内存管理
为了减少频繁向操作系统申请内存的情况,Netty会一次性申请一块较大的内存(由ChunkSize决定,默认为16M),这块内存被称为PoolChunk。
而在一个Chunk下,又分为了一个一个页,叫做Page,默认为8K,即默认情况下一个Chunk有2048个页。
超详细图文详解神秘的 Netty 高性能内存管理 - 知乎 (zhihu.com)
3.1 PoolChunk如何管理Page
PoolChunk通过一个完全二叉树来管理Page,这颗二叉树的深度为12(2^11 = 2048)。
PoolChunk会维护一个memeoryMap数组,这个数组对应着每个节点,它的值代表这个节点之下的第几层还存在未分配的节点。
- 比如说第9层的
memeoryMap值为9,代表这个节点下面的子节点都未被分配 - 若第9层的
memeoryMap为10,代表它本身不可被分配,但第10层有子节点可以被分配 - 若第9层的
memeoryMap为12(树的高度),代表当前节点下的所有子节点都不可分配
那么我们怎么分配呢?
比如我们要15KB的空间,这里会先向上取8的整数,也就是16K,也就是2^1 * 8,拿到指数1,通过depth - 1 = 12 - 1得到11,那么我们只需要去找memeoryMap为11的节点即可。在分配后,父节点的memeoryMap等于两个子节点的最小值。
3.2 Page的管理
一个Page有8K,一般我们的应用程序是用不了这么多的,因此每个Page下会再次分隔。但这次分隔并不是以完全二叉树的形式,因为太占空间了,而是将这8K划分为等长的n份,一般会由PoolSubpage管理,一般分为两类:
- tiny:用于分配小于512字节的内存,一般大小为16B,32B,...,496B,每次增长为16的倍数,共32个。
- small:用于分配大于等于512字节的内存,一般大小为512B、1K、2K,4K。
对于每个块,会有一个bitMap去判断是否使用,可以理解为Java中的BitSet
3.3 Chunk的管理
每个PoolChunk通过PoolArena类来管理,这些Chunk被封装在PoolChunkList类中,这是一个双向链表。
PoolArena有6个PoolChunkList:
- qInit:存储内存利用率 0-25% 的 chunk
- q000:存储内存利用率 1-50% 的 chunk
- q025:存储内存利用率 25-75% 的 chunk
- q050:存储内存利用率 50-100% 的 chunk
- q075:存储内存利用率 75-100%的 chunk
- q100:存储内存利用率 100%的 chunk
PoolArena分配内存的顺序是:q050、q025、q000、qInit、q075
这样分配的好处是可以提高内存的利用率,以及减少链表的遍历次数。
3.4 PoolThreadCache
PoolThreadCache利用了ThreadLocal,每次线程在申请内存时都会优先从这里面获取。
- 在释放已分配的内存块时,不放回到 Chunk 中,而是缓存到 ThreadCache 中
- 在分配内存块时,优先从 ThreadCache 获取。若无法获取到,再从 Chunk 中分配
- 通过这样的方式,既能提高分配效率,又尽可能的避免多线程的同步和竞争
4. 直接内存回收原理
每个ByteBuf都实现了一个ReferenceCounted接口,netty也是直接采用了引用计数法来进行内存回收。
5. 怎么判断ByteBuffer是否处于写模式或读模式
ByteBuffer有三个重要参数:position、limit、capacity,而平常我们说的读模式或写模式只是用来方便我们理解的东西,真正在ByteBuffer的实现里并不存在什么读模式和写模式,也就是说你在"读模式下"仍然可以写。
例如下面的代码:
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
byte[] hello = "hello".getBytes(StandardCharsets.UTF_8);
System.out.println(Arrays.toString(hello));
// "write mode"
byteBuffer.put(hello);
// "read mode"
byteBuffer.flip();
// write again
byteBuffer.put("h".getBytes(StandardCharsets.UTF_8));
while (byteBuffer.hasRemaining()) {
System.out.print(byteBuffer.get() + " ");
}
java
在"读模式"下去写的时候,并不会报错,由于切换到了"读模式",此时position = 0,limit = 写模式的offset,因此在写的时候,会从索引0处开始写,写完后,position变为1,我们再读的话也就只能从索引1读到4了。
如果硬要判断是不是"读模式"或"写模式",可以根据position和limit的值进行判断:
- 如
limit = capacity,表示当前可能为写模式
1. B树和B+树之间的区别
B树有些博客上会写成B-树,部分博客甚至读成了B减树,其实这个减号只是一个连接符,没有任何意义
B-Tree Visualization (usfca.edu)
B+ Tree Visualization (usfca.edu)
B树和B+树的区别:
- B+树只会在叶子节点存储数据,而B树每个节点上都会有数据
- B+树每个叶子节点之间有一个指针乡相连
2. 高度为3的B+树能存多少条数据
MySQL系列(4)— InnoDB数据页结构 - 掘金 (juejin.cn)
在InnoDB中,索引默认使用的数据结构为B+树,而B+树里的每个节点都是一个页,默认的页大小为16KB。
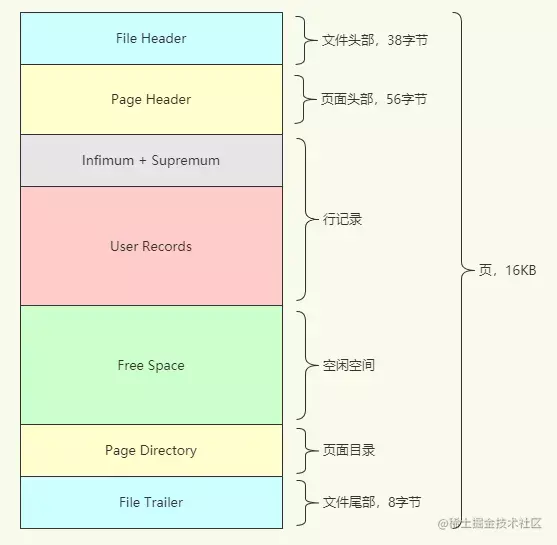
3. 简单说一下InnoDB事务实现原理
事务ACID:
| 名称 | 别名 | 说明 |
|---|---|---|
| Atomicity | 原子性 | 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生 |
| Consistency | 一致性 | 事务前后数据的完整性必须保持一致 |
| Isolation | 隔离性 | 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离 |
| Durability | 持久性 | 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响 |
一文了解InnoDB事务实现原理 - 知乎 (zhihu.com)
上面那个比较深入,下面这个比较好理解一些:
图解InnoDB事务实现原理|Redo Log&Undo Log - 掘金 (juejin.cn)
4.MySql的三大日志是哪些
MySQL三大日志(binlog,redolog,undolog)详解 - 掘金 (juejin.cn)
聊聊MVCC和Next-key Locks - 掘金 (juejin.cn)
细聊 MySQL undo log、redo log、binlog 有什么用?
redolog
redolog 记录的是物理日志。重做日志,用于 mysql 的崩溃恢复。在每次事务提交前,MySQL 都会将事务造成的修改记录成一小段数据,并将一小段输入写入缓冲流中,最后根据特定的策略决定什么时候将缓冲流写入到硬盘中。
redolog 在保存时,是以日志文件组的形式保存的,一个文件组中有多个文件,每个文件组合起来,构成一个类似环状链表的结构。在日志文件组中,分别由 wirte pos 和 checkpoint 保存相应的位置信息。wirte pos 主要保存当前 redolog 写到了哪里。checkpoint 则保存当前 redolog 执行到了哪里。
当write pos 追上 checkpoint 时,也就是 redolog 写满时,MySQL 会被阻塞,此时会停下来将 Buffer Pool 中的脏页刷新到磁盘中,然后标记 redo log 哪些记录可以被擦除,接着对旧的 redo log 记录进行擦除,等擦除完旧记录腾出了空间,checkpoint 就会往后移动,然后 MySQL 恢复正常运行,继续执行新的更新操作。
Note所以,一次 checkpoint 的过程就是脏页刷新到磁盘中变成干净页,然后标记 redo log 哪些记录可以被覆盖的过程。
除了 redolog 满了,下面的情况也会触发 redolog 清理:
- 内存中的脏页百分比超过
innodb_max_dirty_pages_pct(默认为 75) 时 - 内存中的脏页百分比超过
innodb_max_dirty_pages_pct_lwm(默认为 0)时,为 0 时为保持脏页百分比在innodb_max_dirty_pages_pct,当大于 0 时,脏页百分比超过该值后就会开始清理,当超过innodb_max_dirty_pages_pct时,就会用更快地速度清理。
binlog
binlog 存储的是逻辑日志,它会记录 mysql 每次执行的 sql 语句。主要用于 mysql 节点之间的数据同步。binlog 会在事务执行过程中写入binlog cache中,并在事务提交后(发送 commit 命令后)刷新到操作系统的缓存中,之后根据不同的策略决定是否立即刷新操作系统的缓存。
两阶段提交
为了防止 binlog 和 redolog 数据不一致(redolog 刷盘了,binlog没刷),binlog在提交时使用了两阶段提交。其实就是将 redo log 的写入拆成了两个步骤:prepare 和 commit,中间再穿插写入binlog,具体如下:
prepare 阶段(事务提交前):将 XID(内部 XA 事务的 ID) 写入到 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
commit 阶段:把 XID 写入到 binlog,然后将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件,所以 commit 状态也是会刷盘的);
binlog 可以用于崩溃恢复吗
不可以,redolog 可以用于崩溃恢复的必要条件是它拥有 write pos 和 checkpoint 这两个标识,可以记录当前数据哪一段还没有被写入到硬盘中。而 binlog 没有这样的标识,只通过 binlog 无法得知某条数据是否已经写进了硬盘。
binlog 可以干嘛
在文档中提到,binlog 可以:
- 为主从同步数据
- 时间点恢复
这里主要是第二点,具体可以看文档操作:Point-in-Time Recovery Using Binary Log。这个功能主要用于支持在数据库整个备份后,通过 binlog 实现增量备份,从而避免直接备份整个数据库。
5. MySql当前读和快照度
MySQL 的可重复读到底是怎么实现的?图解 ReadView 机制 - 知乎 (zhihu.com)
这里其实有个问题,如果我只是单独的一条查询语句,没有开启事务,那么怎么去快照读呢?
这个我自己查了一下,众所周知,MySql里有一个autocommit属性,对于单条SQL,这个值一定是true,那么是不是说明我们每条SQL都会被认作是一个事务呢?
然后我在官方文档里查了一下:

MySQL :: MySQL 5.7 Reference Manual :: 14.7.2.2 autocommit, Commit, and Rollback
MySQL :: MySQL 8.0 Reference Manual :: 15.7.2.2 autocommit, Commit, and Rollback
不管是8.0还是5.7,都是这样写的,那么就可以说的通了。每次执行单条SQL都会拿到一个事务id,然后再去进行快照读。
那么什么是当前读呢,使用下面的sql语句就是当前读:
# 加共享锁
SELECT ... LOCK IN SHARE MODE
# 加排它锁
SELECT ... FROM UPDATE
sql
这两条语句的原理就是给对应的行加上共享锁(读锁)或排它锁(写锁),当有事务进行增删改时也会加排它锁,对于共享锁,允许多个事务持有(即允许多读),对于排它锁,则只允许一个事务持有(即只能一个人写,且除了自己其它人都不能读)。
在排它锁和共享锁下读的的数据就是当前读,这份数据永远是最新的(此时若有其它事务想要修改相关的行,都会被阻塞)。其它状况则就是快照读了,通过MVCC创建ReadView进行数据的读取。
6. MySql的MVCC
MVCC(Multiversion Concurrency Control)多版本并发控制。
首先在在MVCC下,每个表都会多出几个隐藏的列,分别为隐藏主键(row_id)、事务id(trx_id)、回滚指针(roll_pointer)。
MVCC还有两个重要的组成:undo log(回滚日志)、ReadView。
ReadView 主要有下面几个字段:
| 字段名称 | 说明 | |
|---|---|---|
| m_low_limit_id | "高水位线",读操作不应该读取事务 id 大于等于该值的任何记录 | |
| m_up_limit_id | "低水位线",读操作可以直接读取小于该值的任何记录 | |
| m_creator_trx_id | 创建该 ReadView 的事务 id | |
| m_ids | 当 ReadView 创建时,所有正在运行的事务id | |
| m_low_limit_no | 事务不需要查看事务 id 小于该值的 undolog。小于该值的undolog如果不再被其它 ReadView需要,可以被清除 |
详细的生成规则:
m_low_limit_id: 下一次生成的事务 idm_up_limit_id: 当前还没有提交的、最小的事务 idm_low_limit_no: 所有持久化完毕的、最大的事务 id (小于该 id 的事务已经全部持久化完成)
还需要注意的一点是:
- 在 ReadCommitted 隔离级别下,每次查询都会创建新的 ReadView
- 在 RepeatableRead 隔离级别下,仅第一次查询会创建 ReadView,后续查询全部复用第一次创建的,这样就解决了幻读的问题 (虽然 RepeatableRead 在定义时没有解决幻读,但是在 mysql 的实现中,它就是解决了幻读的,相当于一个是接口,一个是实现)。
其它引用:
7. RepeatableRead真的不能避免幻读吗?
美团三面:一直追问我, MySQL 幻读被彻底解决了吗?_肥肥技术宅的博客-CSDN博客
8. 为什么bin_log不能用作崩溃后的恢复
不定时更新...
达梦8
docker run -d -p 5236:5236 --restart=always --name dm8_01 --privileged=true -e PAGE_SIZE=16 -e LD_LIBRARY_PATH=/opt/dmdbms/bin -e INSTANCE_NAME=dm8_01 -v /data/dm8_01:/opt/dmdbms/data dm8_single:v8.1.2.128_ent_x86_64_ctm_pack4shell
人大金仓
docker run -d -it --privileged=true -p 54321:54321 -v /opt/docker/kingbase-latest/opt/:/opt --name kingbase-latest godmeowicesun/kingbase:latestshell
-
端口: 54321
-
用户名: SYSTEM
-
密码: 123456
-
默认数据库: TEST
mysql
docker run --name mysql -p 3307:3306 -e MYSQL_ROOT_PASSWORD=123456 --privileged -v /home/vagrant/mysql5.7/data:/var/lib/mysql -d mysql:5.7.42shell
进入容器修改配置文件:
cat <<EOF > /etc/mysql/my.cnf
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
init_connect='SET collation_connection = utf8mb4_unicode_ci'
init_connect='SET NAMES utf8mb4'
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
skip-character-set-client-handshake
lower_case_table_names = 1
EOF
bash
执行下面的sql:
set character_set_connection=utf8mb4;
/*数据库的编码*/
set character_set_database=utf8mb4;
/*结果集的编码*/
set character_set_results=utf8mb4;
/*数据库服务器的编码*/
set character_set_server=utf8mb4;
set character_set_system=utf8mb4;
set collation_connection=utf8mb4;
set collation_database=utf8mb4;
set collation_server=utf8mb4;
show variables like '%character%';
sql
opengauss5.0.0
docker run --hostname=fcdea04e2440 --env=GS_PASSWORD=P@ssw0rd --env=PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin --env=EXEC_GOSU=gosu-amd64 --env=GOSU_VERSION=1.12 --env=PGDATA=/var/lib/opengauss/data --volume=/var/lib/opengauss/data:/var/lib/opengauss/data --privileged --workdir=/ -p 5432:5432 --restart=no --label='CREATE_DATE=2022-10' --label='GAUSS_SERVER=openGauss-5.0.0' --label='MAIL=heguofeng@huawei.com' --runtime=runc -d opengauss/opengauss:5.0.0shell
opengauss2.1.0
docker run --name opengauss2.1.0 --privileged=true -d -e GS_PASSWORD=P@ssw0rd -u root -p 5432:5432 enmotech/opengauss:2.1.0shell
oracel
docker run -d --name oracle-db -p 1521:1521 --privileged -e ORACLE_PWD=123456 -e ORACLE_CHARACTERSET=utf8mb4 -v /opt/oracle/oradata container-registry.oracle.com/database/free:latestshell
redis
docker run -d --name redis --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis --requirepass 123456 --appendonly yes --port 6381shell
nginx
docker run --name nginx -v /host/path/nginx.conf:/etc/nginx/nginx.conf:ro -d nginx:stable-perlbash