IceOfSummerの博客还是自己搭的博客靠谱后面一辈子的博客都在这了!
2023/11/27
可变参数
写过ReactNative的都知道,ReactNavigation库里面有一个非常牛逼的类型声明,它可以根据你传入的参数,来判断是否需要第二个参数。
例如下面的定义:
interface RouteDef {
home: undefined
shop: {
time: number
}
}
typescript
那么它的路由方法就变得很牛逼了:
// 实际的泛型肯定不是这么传的,因为我写的时候没用RN了,所有忘了咋用的了
const nav = useNavigation<RouteDef>()
// 正确
nav('home')
// 错误: ts提示这里只需要一个参数
nav('home', undefined)
// 错误,ts提示这里需要两个参数
nav('shop')
// 正确
nav('shop', { time: Date.now() })
// 错误: 第二个参数需要{ time: number }类型,而提供的是number
nav('shop', Date.now())
typescript
很牛逼啊有没有,连参数的数量都给你变了!而且还能根据属性的定义来决定参数。
那么这玩意具体是咋写的呢?我仔细研究了一下,研究完后,仿佛开启了新大门!
我这里直接写一个Demo来看:
type EmitFuncArgs<Events, Key extends keyof Events> = void extends Events[Key]
? [evt: Key]
: [evt: Key, data: Events[Key]]
type EmitFunc<Events> = <T extends keyof Events> (...args: EmitFuncArgs<Events, T>) => string
export interface AppEvents {
ON_LOGOUT: string
ON_LOGIN: void
}
typescript
先来看下面的EmitFunc定义,首先这玩意的泛型接收一个Events类型(直接把它看成下面的AppEvents接口就行),然后它的参数是EmitFuncArgs
决定的。
来看EmitFuncArgs,可以发现这玩意居然返回了一个数组,并且还用上了三目运算符。
到了这里,大伙都应该可以理解是怎么玩的了,就是首先判断值是不是void,如果是,则返回一个长度为1的数组,反之则返回长度为2的数组,其中的第二个 参数为接口定义的类型。
2023/11/10
首先来看一段代码(Java17, Java8同样也有这个问题):
Runtime runtime = Runtime.getRuntime();
runtime.exec("docker exec mysql-test2 mysql -ubim -pxx -h11.11.11.11 -P3306 bim -e \"use bim;source bim.sql;\"");
java
这段代码是用来执行mysqldump备份出来的mysql文件,咋一看好像没问题。
运行后,byd好像也确实没什么问题👿👿👿
如果真的没问题就好了,那么也不会有这篇博客了。
写完后打包丢到Linux上去跑的时候,你就会发现。。。
运行后发现执行失败了,exitCode为1,看了一下它的输出,它居然直接把mysql的帮助菜单给打印出来了???
见过离谱的,没见过这么离谱的,我这个指令可是跟帮助菜单一点关系都没有啊?
如果大家去搜java怎么去执行命令行指令的时候,可能会得到两个结果,一种就是用Runtime,另外一个就是用ProcessBuilder,大部分人可能都会用Runtime,因为这玩意给ProcessBuilder封装了一层,用起来方便,直接一个exec把指令丢进去就可以了。
也就是因为这个,突然想起来之前在python里面,想要执行shell命令必须要把指令以数组的形式传进去(其实也可以使用shell=True参数),而ProcessBuilder也是这样,你直接丢一个字符串进去是执行不了的,必须要传数组进去。
到这里就怀疑Runtime是不是直接暴力调用了split(" "),然后把参数丢给ProcessBuilder,结果看了下源码,还真是这样:
public Process exec(String command, String[] envp, File dir)
throws IOException {
if (command.isEmpty())
throw new IllegalArgumentException("Empty command");
StringTokenizer st = new StringTokenizer(command);
String[] cmdarray = new String[st.countTokens()];
for (int i = 0; st.hasMoreTokens(); i++)
cmdarray[i] = st.nextToken();
return exec(cmdarray, envp, dir);
}
java
StringTokenizer可能大家没见过,但是如果你用java写算法,并且了解过输入优化,你就会知到这玩意是干嘛的。简单点来说它的效果和Scanner一样,但是效率更高(如果你写过算法就知道这玩意速度吊打Scanner),Scanner就不多讲了,感觉是个人就用过。。。
如果你还看不懂,没事,我直接给你上图:
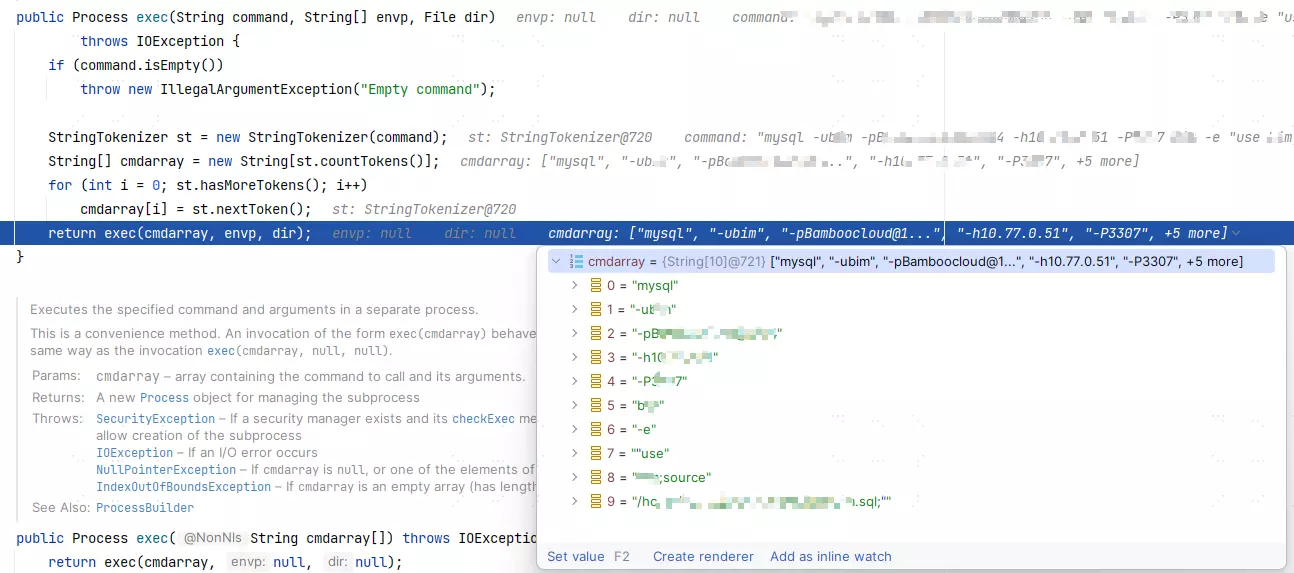
可以发现我们后面用双引号包裹起来的参数被分开了,实际传到mysql那里就会导致执行失败。
但是这玩意在windows上能执行成功也是很离谱的。
知到原因后,直接改用ProcessBuilder手动控制参数:
Process process = new ProcessBuilder(backupConfig.getMysqlPath(),
"-u" + backupConfig.getUsername(),
"-p" + backupConfig.getPassword(),
"-h" + backupConfig.getHost(),
"-P" + backupConfig.getPort(),
"-e",
String.format("\"use %s;source %s;\"", ignore, ignore))
// 标准错误流重定向到标准输出,方便拿错误信息
.redirectErrorStream(true)
.start();
java
看到我的String.format没,我这里用引号包起来了好让他们是一个整体。
完?。。
丢到服务器上跑,结果又报错了👿,不过至少这次没打帮助菜单,提示""use %s;source %s;""不是一个mysql指令。
byd原来引号是自作多情多加上了,最后把引号给删掉就能跑起来了。。
这bug也是花了我挺多时间的吧,一开始以为是mysql的问题,结果居然是jdk自己的问题。
2023/09/04
1. 前言
公司要求项目去适配高斯数据库,看了一下,高斯数据库就可以当做postgresql用,有啥问题把高斯换成postgresql来查就行。 其实整个项目没有太大的变动,只是几个函数需要改一下,如果用mybatis就更简单了:
@Bean
public VendorDatabaseIdProvider vendorDatabaseIdProvider() {
VendorDatabaseIdProvider vendorDatabaseIdProvider = new VendorDatabaseIdProvider();
Properties properties = new Properties();
properties.put("MySQL", "mysql");
properties.put("Oracle", "oracle");
properties.put("PostgreSQL", "pgsql");
properties.put("DM DBMS", "dm");
vendorDatabaseIdProvider.setProperties(properties);
return vendorDatabaseIdProvider;
}
@Bean
public SqlSessionFactoryBean sqlSessionFactoryBean(@Qualifier("dataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(dataSource);
factoryBean.setDatabaseIdProvider(databaseIdProvider());
factoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapperLocations));
return factoryBean;
}
java
添加上面配置后,碰到不兼容的函数可以这样处理:
<select id="maxid" databaseId="pgsql" resultType="int">
select another_max(power_id) from tb_xx
</select>
<!-- 给一个默认的 -->
<select id="maxid" resultType="int">
select max(power_id) from tb_xx
</select>
xml
这样idea会爆红,可能看着有点不舒服。
也可以考虑这样写:
<choose>
<when test="_databaseId == 'oracle'">
xxx
</when>
<when test="_databaseId == 'dm'">
xxx
</when>
<when test="_databaseId == 'mysql'">
xxx
</when>
<when test="_databaseId == 'informix' or _databaseId == 'gbase8s'">
xxx
</when>
<otherwise>
xxx
</otherwise>
</choose>
xml
两种都可以,如果太复杂了建议用第一种。
本来到这,已经完事大吉了,就去mapper里面去检查一下有没有哪个函数是高斯没有的,然后改一下就行。
结果,万万没想到,项目里面有拿StringBuilder搞SQL拼串的代码,结果写的全是坑,这玩意狠狠折磨了我好几个星期!
2. 别名问题
SELECT id AS userId FROM user
sql
上面这个SQL很简单,就是查用户id,然后起个别名叫userId,乍一看好像没什么,下面我放个图,大家来找不同:
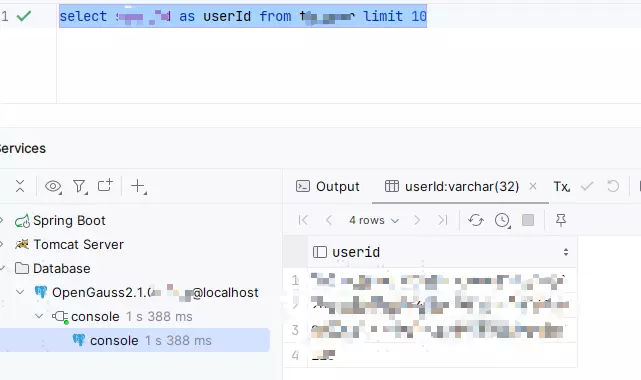
发现了吗?仔细看一下userId,有没有发现查出来全部变成小写了?
在我们项目代码里,直接从结果集里面拿userId,结果拿不到爆空指针!
原本我以为是配置问题,把大小写搞得不敏感了,结果去网上搜了一下,结果只有表名能修改大小写敏感。
所以要怎么改呢,其实只需要在别名的左右加上双引号就行了:
SELECT id AS "userId" FROM user
sql
这个操作同样兼容mysql。
3. COUNT(*)
SELECT COUNT(*) FROM userId
sql
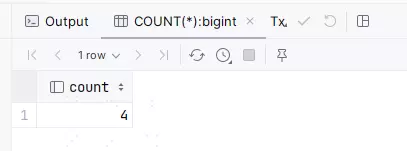
又是一个非常简单的SQL,然后咱们又来找不同:
高斯的结果:
mysql的结果:
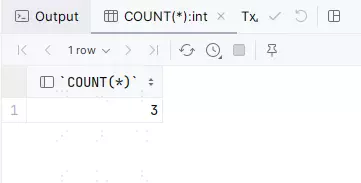
相信一眼就能看出来,mysql拿需要用COUNT(*),而高斯则需要用count拿。
这里最好的解决办法就只有取别名了,全部都叫同一个就行了。
不兼容的函数/语法
| MySql函数名 | 高斯函数名 | 说明 |
|---|---|---|
| LIMIT offset, size | LIMIT size OFFSET offset | 高斯不支持mysql的语法,Mysql支持高斯的语法,更换时注意offset和size的位置需要交换 |
| group_concat(col) | array_to_string(array_agg(col), ',') | group_concat |
| date_format(col, '%Y-%m-%d') | to_char(col, 'yyyy-mm-dd') | 日期转字符串 |
| delete from tb1, tb2 | 不兼容,推荐使用子查询 | mysql 删除时选择两张表,高斯不支持 |
| IFNULL(xx, fallback) | COALESCE(xx, fallback) | 当列为空时使用默认值 |
2023/08/30
1. 起因
由于最近公司要求给tomcat配置https,本来以为只是简单的塞个证书和私钥就行了:
<Connector port="8443" protocol="org.apache.coyote.http11.Http11NioProtocol" SSLEnabled="true" >
<SSLHostConfig protocols="TLSv1.2" sslProtocol="TLS">
<Certificate certificateKeyFile="conf/server.key"
certificateFile="conf/server.crt"
type="RSA"/>
</SSLHostConfig>
</Connector>
xml
结果要求用jks证书文件,彳亍:
<Connector port="8443" protocol="org.apache.coyote.http11.Http11NioProtocol"
sslProtocol="TLS"
protocols="TLSv1.2"
SSLEnabled="true"
keystoreFile="conf/server.keystore"
keystorePass="xxxx"/>
xml
本以为万事大吉,结果甲方爸爸因为密码是直接写的明文,要求我们必须把密码穿成加密的🥲。
不过还好顺带也给了我份博客:tomcat安全配置之证书密码加密存储
2. tomcat配置https
2.1 编写实现类
其实这份博客已经说的很清楚了,只需要继承Http11NioProtocol这个类就可以了
博客里用的
Http11Protocol,这个类已经被标记为@Deprecated的了,所以我们直接用它的父类,效果是一样的。
但是这个博客还是不太完整,这个类怎么打jar包?Http11Protocol从哪里来?打了的jar包丢在哪里?博客里都没有说明。
这里我自己研究了一下,首先创建一个maven项目,pom.xml添加依赖:
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-coyote</artifactId>
<version>8.5.87</version>
<scope>provided</scope>
</dependency>
xml
注意scope是provided。
之后就可以直接写代码了:
import org.apache.coyote.http11.Http11NioProtocol;
public class EncryptedHttp11Protocol extends Http11NioProtocol {
@Override
public void init() throws Exception {
// 进行你自己的密码获取逻辑
setKeystorePass("xxx");
super.init();
}
}
java
写完直接用maven打包:
mvn package -DskipTestsshell
然后丢到tomcat目录的lib文件夹里就可以了。
最后配置server.xml:
<Connector port="8443" protocol="xxxxxxx.EncryptedHttp11Protocol" SSLEnabled="true"
keystoreFile="conf/server.keystore"
sslProtocol="TLS">
</Connector>
xml
注意protocol属性要改成你自己的实现类
2.2 设置环境变量
由于jks被加密,需要提供密码,因此推荐的方法是通过系统环境变量来提供(这里直接根据自己的机器设置即可)。 在java代码里这样获取系统环境变量:
String value = System.getenv(key);
java
2.3 设置命令行参数
也可以通过设置tomcat命令行参数来传输秘钥, 在tomcat的bin目录下创建setenv.bat(windows) / setenv.sh (linux)文件,并且配置相关参数即可。
windows:
set "JAVA_OPTS=-DsecretKey=xxxx -DsercretKey2=xxxx"
bat
linux:
JAVA_OPTS="-DsecretKey=xxxx -DsercretKey2=xxxx"shell
之后在代码中这样获取:
String value = System.getProperty(key);
java
3. SpringBoot内嵌tomcat配置https
你说的对,但是我是SpringBoot内嵌tomcat!
公司的众多模块中,偏偏就是有一个SpringBoot项目,这玩意用的内嵌tomcat,上面的方法都用不了👎👎👎。
首先我们要知道SpringBoot项目怎么开启https:
server:
ssl:
enabled: true
key-store: classpath:server.keystore
key-store-password: xxxxxx
yaml
我们只需要找到一个方法在配置ssl前修改配置,提供密码即可。
你别说,还真被我找到了,在启动类添加下面的代码:
@Bean
public WebServerFactoryCustomizer<UndertowServletWebServerFactory> webServerFactoryCustomizer() {
return factory -> {
Ssl ssl = factory.getSsl();
if (ssl == null || !ssl.isEnabled()) {
return;
}
// ... 获取秘钥
ssl.setKeyStorePassword("xxxx");
};
}
java
甚至你在这里还可以引用刚才为tomcat准备的jar包,直接使用里面的秘钥获取逻辑,就不用再写一遍了√。
4. 其它:由证书和私钥生成jks文件
首先执行命令生成p12文件(输入后会要求输入密码,直接填上你要的密码就行):
openssl pkcs12 -export -in server.crt -inkey server.key -out server.p12shell
输完后执行:
keytool -importkeystore -v -srckeystore server.p12 -srcstoretype pkcs12 -srcstorepass 上面的密码 -destkeystore server.keystore -destoretype jks -deststorepass 上面的密码shell
这里如果jdk版本过低会报错:
keytool 错误: java.io.IOException: parseAlgParameters failed: ObjectIdentifier() -- data isn't an object ID (tag = 48) java.io.IOException: parseAlgParameters failed: ObjectIdentifier() -- data isn't an object ID (tag = 48) at sun.security.pkcs12.PKCS12KeyStore.parseAlgParameters(PKCS12KeyStore.java:816) at sun.security.pkcs12.PKCS12KeyStore.engineLoad(PKCS12KeyStore.java:2018) at java.security.KeyStore.load(KeyStore.java:1445) at sun.security.tools.keytool.Main.loadSourceKeyStore(Main.java:2040) at sun.security.tools.keytool.Main.doCommands(Main.java:1067) at sun.security.tools.keytool.Main.run(Main.java:366) at sun.security.tools.keytool.Main.main(Main.java:359) Caused by: java.io.IOException: ObjectIdentifier() -- data isn't an object ID (tag = 48) at sun.security.util.ObjectIdentifier.<init>(ObjectIdentifier.java:257) at sun.security.util.DerInputStream.getOID(DerInputStream.java:314) at com.sun.crypto.provider.PBES2Parameters.engineInit(PBES2Parameters.java:267) at java.security.AlgorithmParameters.init(AlgorithmParameters.java:293) at sun.security.pkcs12.PKCS12KeyStore.parseAlgParameters(PKCS12KeyStore.java:812) ... 6 morejava
这里用的jdk1.8.0_241导致的报错,换成jdk-11.0.18可以正常执行,其它版本暂未测试。