一主二从
Note参考: https://blog.csdn.net/qq_41786285/article/details/109304126
准备配置
mkdir -p /data/mysql/ mkdir /data/mysql/mysql20001 mkdir /data/mysql/mysql20002 mkdir /data/mysql/mysql20003shell
mysql20001 是主数据库,mysql20002 和 mysql20003 是从数据库。
修改主节点配置文件(/data/mysql/my1.cnf):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 # 可选 binlog_format = mixed # 下面的配置是必须的 server-id = 1 log_bin = mysql-bin binlog_ignore_db=information_schema,performance_schema,mysql,syscnf
修改从节点配置(/data/mysql/my2.cnf):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 # 下面的配置是必须的 server-id = 2 relay-log = relay-log-bin relay-log-index = slave-relay-bin.indexcnf
Important记住配置另外一个从库的时候需要修改 server-id
最后修改目录权限:
useradd mysql groupadd mysql chown -R mysql /data/mysql chgrp -R mysql /data/mysqlshell
启动容器
Important可以使用我自己上传的镜像:
docker pull ccr.ccs.tencentyun.com/icebing-repo/mysql:5.7.42
ID=1 docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42shell
注意参数中的 -u 27:27,这里是使用了 uid:gid 的格式,使用其它格式会导致权限不足:
2024-12-03 14:36:24+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 5.7.42-1.el7 started. 2024-12-03 14:36:24+00:00 [Note] [Entrypoint]: Initializing database files mysqld: Can't create directory '/var/lib/mysql/' (Errcode: 17 - File exists) 2024-12-03T14:36:24.891299Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details). 2024-12-03T14:36:24.893084Z 0 [ERROR] Abortinglog
查看 uid 和 gid:
[root@localhost mysql]# id mysql uid=27(mysql) gid=27(mysql) groups=27(mysql)shell
同样的方式启动另外两台从节点。
从节点加入集群
登录主节点执行:
grant replication slave on *.* to 'myslave'@'172.17.0.%' identified by '123456';
flush privileges;
sql
注意这里的 ip 地址,容器默认情况下是桥接模式,容器的 ip 不是宿主机的 ip,具体 ip 网段可以用下面的命令看:
docker inspect mysql20002 | grep Networks -A 16shell
找到 Gateway 字段,单独使用这个 ip 或者直接使用对应的网段。
查看主节点状态:
# 主库执行
show master status;
sql

这里需要记住上面的 File 和 Position,之后在从节点中执行下面的 sql 来加入集群:
# 从库执行
change master to master_host ='10.77.0.38',
master_port = 20001,
master_user ='myslave',
master_password ='123456',
master_log_file ='mysql-bin.000004',
master_log_pos =154;
show slave status;
start slave;
sql
这里我们先只让一台加进去,后面一台我们待会尝试中途加入。
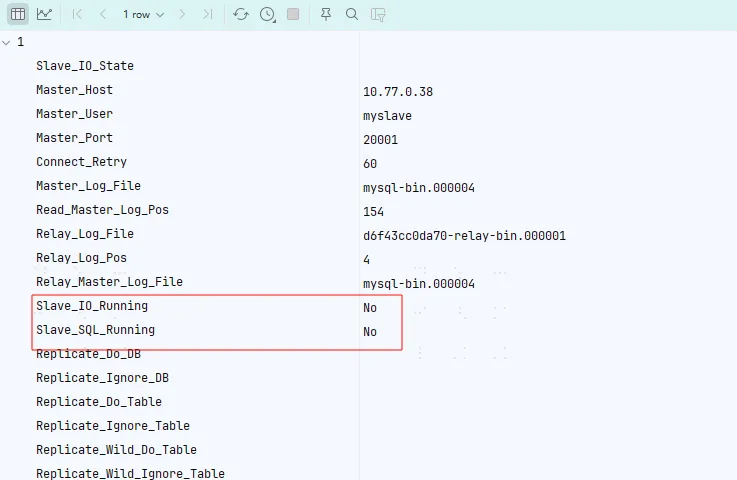
这里等到打框框的这两个值都变成 YES 就完成了。但是我这里把配置搞错了...导致一直加不进去,所以这里额外研究了一下节点怎么退出集群。
节点退出集群
使用下面的命令之一退出集群
# 停止从主节点的同步,直到使用 START SLAVE
STOP SLAVE;
# 删除同步的内容
RESET SLAVE;
sql
部分情况下由于初始的错误配置可能导致停不掉,这时候就直接强制停止从节点重新部署一个就行了,对主节点没有影响的。
测试从节点
在主库执行下面的 sql:
create database slave_test;
use slave_test;
CREATE table slave_data(
id varchar(20) primary key ,
tm timestamp
);
INSERT INTO slave_data value ('1', CURRENT_TIMESTAMP());
sql
然后可以查看从节点是否创建相关的数据。
从节点扩容
Note参考: https://blog.csdn.net/anddyhua/article/details/116240478
我们这里留了一台节点还没有加入集群,这里我们专门来测试从节点的水平扩容。这里我们使用 xtrabackup 来进行备份。
首先下载 xtrabackup,这里 Mysql 5.7 只能使用 2.4 版本的。下载完成后解压,进入 bin 目录,执行下列命令进行备份:
./xtrabackup --backup --target-dir=/data/mysql/backup/bakup_`date +"%F_%H_%M_%S"` --user=root --host=10.77.0.38 --port=20001 --password=123456 --datadir=/data/mysql/mysql20001shell
备份完成后查看目录:
[root@localhost bakup_2024-12-05_00_28_08]# ll total 77876 -rw-r----- 1 root root 487 Dec 5 00:28 backup-my.cnf -rw-r----- 1 root root 661 Dec 5 00:28 ib_buffer_pool -rw-r----- 1 root root 79691776 Dec 5 00:28 ibdata1 drwxr-x--- 2 root root 4096 Dec 5 00:28 mysql drwxr-x--- 2 root root 8192 Dec 5 00:28 performance_schema drwxr-x--- 2 root root 64 Dec 5 00:28 slave_test drwxr-x--- 2 root root 8192 Dec 5 00:28 sys -rw-r----- 1 root root 21 Dec 5 00:28 xtrabackup_binlog_info -rw-r----- 1 root root 138 Dec 5 00:28 xtrabackup_checkpoints -rw-r----- 1 root root 587 Dec 5 00:28 xtrabackup_info -rw-r----- 1 root root 2560 Dec 5 00:28 xtrabackup_logfileshell
可以发现几乎是和 mysql 数据目录一样的结构。之后我们将备份的内容复制到第二个从节点的数据目录中(/data/mysql/mysql20003)。这里需要注意权限问题,复制过来后需要把权限给 mysql 用户。
启动从库(和之前相同的命令):
ID=3 docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42shell
由于我们在备份的过程中,主节点仍然可以写入数据,所以导致我们备份的数据不一定是最新的,所以在加入集群的时候不能直接使用 show master status 中的 binlog 位置。这里我们需要根据备份目录中 xtrabackup_info 文件来确定具体的位置:
[root@localhost mysql20003]# cat xtrabackup_info uuid = c333e3de-b25c-11ef-81e2-0242ac110002 name = tool_name = xtrabackup tool_command = --backup --target-dir=/data/mysql/backup/bakup_2024-12-05_00_28_08 --user=root --host=10.77.0.38 --port=20001 --password=... --datadir=/data/mysql/mysql20001 tool_version = 2.4.29 ibbackup_version = 2.4.29 server_version = 5.7.42-log start_time = 2024-12-05 00:28:08 end_time = 2024-12-05 00:28:15 lock_time = 4 binlog_pos = filename 'mysql-bin.000006', position '154' innodb_from_lsn = 0 innodb_to_lsn = 12232730 partial = N incremental = N format = file compact = N compressed = N encrypted = Nshell
这里可以看到 binlog_pos 的值,表示当前 binlog 读到了哪里,我们根据这个值来加入主节点:
# 从库执行
change master to master_host ='10.77.0.38',
master_port = 20001,
master_user ='myslave',
master_password ='123456',
master_log_file ='mysql-bin.000006',
master_log_pos =154;
start slave;
show slave status;
sql
最终等待 SLAVE_IO 和 SALVE_SQL 都变成 YES, 从库就加入成功了。
主主架构
主主架构是指系统中有两个 mysql 主数据库,它们相互读写,互相同步数据。相比于单纯的一主多从,主主架构最大的优势就是提供了主节点的高可用
关于读写分离
应用层读写分类
对于简单的集群,例如上面的一主两从,我们可以使用下面的方式在应用的层面实现读写分离:
jdbc:mysql:replication://[source host][:port],[replica host 1][:port][,[replica host 2][:port]]...[/[database]] [?propertyName1=propertyValue1[&propertyName2=propertyValue2]...]plaintext
仅 Java 可用:官方文档。
但是有些语言的驱动可能没有提供读写分离的功能,这个时候可以选择自己在应用层实现。可以参考上面 mysql 文档中的实现,当关闭了只读模式和自动提交,那么后续的 sql 都发送到主节点,否则发送到从节点。
使用中间件实现读写分离
如果不想写代码,可以通过加一个中间件来实现。目前我可以找到的,距离上一次提交最近的中间件是:mycat。
其它的这些全都没有维护了:
个人还是推荐直接在应用层解决吧,毕竟这里还要单独启动一个服务,搞不好中间件就成性能瓶颈了?
多主架构
架构图:
图是自动生成的,可能会有点丑
主主架构相比与一主多从架构,最大的区别就是提供了主节点的高可用,搭配 keepalived 等其它工具,可以快速切换主节点,大大降低了系统的恢复时间。而一主多从架构,只能手动切换主节点,容灾能力低。
但这种架构有下面的缺点:
- 假设上图中的 mysql20001 挂了后,keepalived 自动将写流量切换到 mysql20002 上。当 mysql20001 恢复后重新加入集群,如果不做任何调整,此后将没有任何流量会发送到 mysql20001,除非 mysql20002 挂了或者手动切换主备。
- 主节点挂了后,如果备用的主节点数据还没同步完或者还没开始同步,则会导致数据不一致,这里可以通过修改复制方式来缓解或解决。
准备配置文件
这里我们还是用之前一主两从的配置,先重置掉所有数据:
docker rm mysql20001 -f
docker rm mysql20002 -f
docker rm mysql20003 -f
rm -rf /data/mysql/mysql20001/*
rm -rf /data/mysql/mysql20002/*
rm -rf /data/mysql/mysql20003/*
bash
修改 /data/mysql/my1.cnf,添加下面的内容:
auto_increment_increment=1 auto_increment_offset=1cnf
修改 /data/mysql/my2.cnf,添加下面的内容:
auto_increment_increment=2 auto_increment_offset=2 log_bin=mysql-bin binlog_format=mixed binlog_ignore_db=information_schema,performance_schema,mysql,sys log_slave_updates=ONcnf
这里出现了两个个新的参数:auto_increment_increment、auto_increment_offset 作用分别如下:
auto_increment_increment: 自增主键每次增长多少auto_increment_offset: 自增主键从哪里开始增长- log_slave_updates: 是否将副本(从)服务器从副本源服务器收到的更新写到 binlog 中,默认关闭(mysql8 默认开启,坑了我一波,一开始看错文档了)。这个配置常用于级联架构,例如你可以给一个从库开启这个,然后把这个从库"当成主库",给它加几个从库,达到类似于
A -> B -> C的数据库架构。
启动容器
相同的命令启动容器:
ID=1
docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42
ID=2
docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42
ID=3
docker run --name mysql2000$ID -u 27:27 -p 2000$ID:3306 -e MYSQL_ROOT_PASSWORD=123456 -v /data/mysql/mysql2000${ID}/:/var/lib/mysql/ -v /data/mysql/my${ID}.cnf:/etc/mysql/my.cnf -d mysql:5.7.42
bash
在 mysql20001 和 mysql20002 上创建账号:
grant replication slave on *.* to 'myslave'@'172.17.0.%' identified by '123456';
sql
网段还是要用容器的网段,不是宿主机的!最后相互连接,注意参数需要根据实际情况修改:
change master to master_host ='10.77.0.38',
master_port = 20001,
master_user ='myslave',
master_password ='123456',
master_log_file ='mysql-bin.000004',
master_log_pos =154;
start slave ;
show slave status ;
sql
测试同步,任意主数据库上执行:
create database slave_test;
use slave_test;
CREATE table slave_data(
id varchar(20) primary key ,
tm timestamp
);
INSERT INTO slave_data value ('1', CURRENT_TIMESTAMP());
sql
在另外一个数据库执行:
use slave_test;
INSERT INTO slave_data value ('2', CURRENT_TIMESTAMP());
sql
可以发现两个主库都可以写,并且可以相互同步,而且没有出现任何报错。
最后使用相同的方法,让从库连接上备用主库,进行读写分离(注意加入备用主库时的 pos 需要用最开始的位置或者手动使用 xtrabackup 进行备份后再加入也可以)
最后我们只需要用 keepalived 给两台主库配置上高可用,我们的主主架构就完成了!
总结
至此,我们已经学会 mysql 集群中最基础的部署架构了,在 mysql 中,主从只是一个相对的概念,一个节点既可以是"主"又可以"从",例如我们在主主中提过一嘴的级联架构:
A -> B -> C | -> D | -> Eplaintext
其中 A 为一个主库,B、C、D 和 E 都是从库,但是 C、D、E 的"主库" 是 B,这种架构可以分担 A 的 IO 压力,让写操作更快。
另附配置文件(my1.cnf):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 server_id=1 log_bin=mysql-bin binlog_format=mixed log-slave-updates=true binlog_ignore_db=information_schema,performance_schema,mysql,sys auto_increment_increment=1 auto_increment_offset=1cnf
my2.cnf:
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 relay-log = relay-log-bin relay-log-index = slave-relay-bin.index server-id = 2 auto_increment_increment=2 auto_increment_offset=2 log_bin=mysql-bin binlog_format=mixed binlog_ignore_db=information_schema,performance_schema,mysql,sys log_slave_updates=ONcnf
my3.cnf 没有什么好看的,就是寻常的从库配置。
循环复制问题
我们前面提到开启 log_slave_updates 后, mysql 会把从副本服务器同步的数据也写到自己的 binlog 里面,那么会不会出现这种情况:假设 A 和 B 两个主库都开启这个配置 A 写入一条数据, B 同步后写入 binlog, 然后 A 发现 B binlog 写了新东西,然后去同步,同步完后 B 发现 A 又写了新东西...
就和之前说的一样, mysql 中的主从都是相对的, 所以 mysql 也没有限制这种循环依赖(实际不会这么用,有点像吃饱了没事干...)。
这里如果感兴趣可以自己部署试一下,实际的效果是并不会出现上面的无限同步效果,但是开启后两台主库的 binlog 状态(show master status)会保持相同,只有一台开的时候是不会相同的。
那么 mysql 怎么避免的呢?很简单,判断 binlog 的 server-id,如果是自己的就不同步。
例如在 server-id 为 1 的主库执行下面的 sql 语句:
INSERT INTO slave_data value ('6', CURRENT_TIMESTAMP());
sql
使用 mysqlbinlog 查看 binlog(无关的内容被省略):
#241209 21:17:24 server id 1 end_log_pos 606 CRC32 0xec624c47 Anonymous_GTID last_committed=1 sequence_number=2 rbr_only=no SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/; # at 606 #241209 21:17:24 server id 1 end_log_pos 705 CRC32 0xb3303223 Query thread_id=5 exec_time=0 error_code=0 SET TIMESTAMP=1733750244/*!*/; BEGIN /*!*/; # at 705 #241209 21:17:24 server id 1 end_log_pos 897 CRC32 0x54a64039 Query thread_id=5 exec_time=0 error_code=0 SET TIMESTAMP=1733750244/*!*/; /* ApplicationName=IntelliJ IDEA 2024.3 */ INSERT INTO slave_data value ('5', CURRENT_TIMESTAMP()) /*!*/; # at 897 #241209 21:17:24 server id 1 end_log_pos 928 CRC32 0x941d43ff Xid = 77 COMMIT/*!*/; SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/; DELIMITER ; # End of log file /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;log
可以发现 binlog 是带上了 server-id 的,这样就可以完美避免上面的循环同步的问题了。
主从复制开启 GTID
GTID (Golobal Transaction ID) 可以简单理解为使用雪花算法计算的一个全局唯一 id。
再简单理解一点就是:
- 全局唯一 id
- 递增
格式为:数据库UUID:XID。
它的主要作用就是方便我们创建从库,我们在使用 change master 命令时只需要将 master_auto_position 设置为 1 就可以了,不再需要我们去看主库的状态了。
相当于把 binlog file 和 position 这种不连续的值转换成连续的 id, 只需要告诉 mysql id 从哪里开始就行了, mysql 可以自己推断出下一个 id 然后去同步。
这个 id 直接保存在表中,使用select * from mysql.gtid_executed就可以看到,所以说我们备份的时候相当于直接记录了起始位置到表中。
配置 GTID
这里我们简单搭个一主一从。主库配置(/data/mysql/my1.cnf):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 server_id=1 log_bin=mysql-bin binlog_format=mixed binlog_ignore_db=information_schema,performance_schema,mysql,sys # 开启 gtid gtid-mode=on enforce_gtid_consistency = oncnf
my2.cnf(就是寻常从库配置):
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake lower_case_table_names = 1 server_id=2 # 开启 gtid gtid-mode=on enforce_gtid_consistency = oncnf
启动容器,主库创建账号,这里命令大家翻前面的吧。。。都是一样的,实在懒得写了。
最后,从库加入主库:
change master to master_host ='10.77.0.38',
master_port = 20001,
master_user ='myslave',
master_password ='123456',
master_auto_position = 1;
sql
使用 select @@server_uuid 既可查看当前数据库的 uuid,在主库使用 show global variables like 'gtid_executed' 既可查看当前 gtid 状态:
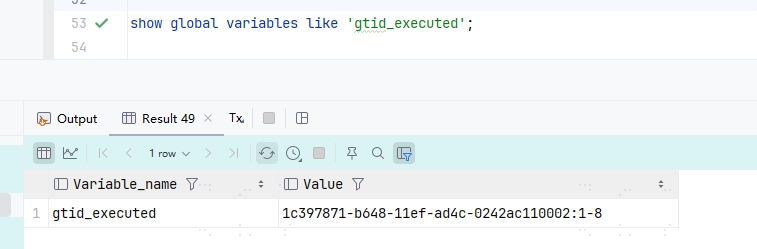
可以发现后面是 1-8,说明有 8 条数据,我们再来看下从库的执行状态,使用 select * from mysql.gtid_executed:
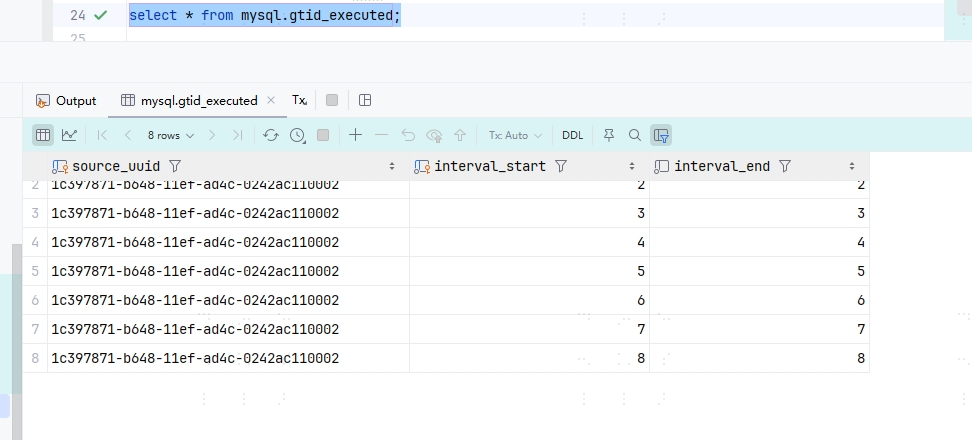
可以发现正好 8 条数据。这里还有一个 interval_end 数据,这里是 mysql 在后续数据量大了之后,会帮我们对数据压缩,具体的实现就是将 start 和 end 设置成一个范围。
最后推荐看一下这个:MySQL 中的集群部署方案,我们前面相当于只介绍了 MySQL Replication 和 MMM, 实际还有很多部署方案。
因为我也没有在生产上实际用过 mysql 集群。。。所以我无法给出一个具体的评价, 但无论如何, 绝大部分架构都是根据MySQL Replication 和 MMM 这两种架构衍生的,所以还是很有必要掌握的。
筛选唯一值
关于这个操作,网上的操作要么是直接用自带的 删除重复值,或者 高级筛选 直接创建一个新的表格。但是这俩个操作有一个最大的问题:重复的值都被删除了。
假如我有一个列保存文件名,另外一个列保存文件中的一些关键内容,一个文件中可能有多个关键内容,也就是一个文件有多行。我删除重复值只是想看一下有哪些文件,看完又需要恢复,那么这个操作就非常不友好了。
这个时候就要请出我们的 COUNTIF 了。
先直接看效果:
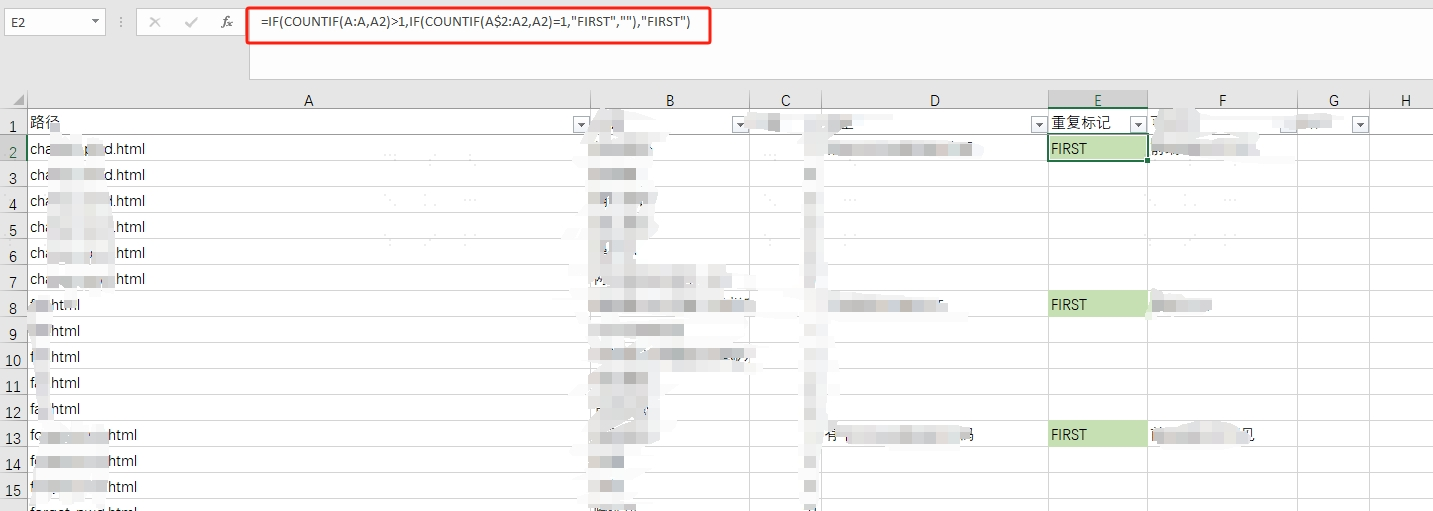
Note这里绿色背景是其它的效果,这里直接忽略就行.
可以发现,所有项目的第一个都会被标记出来,之后我们直接使用普通的 筛选,筛选出值为 FIRST 的行就可以了。
使用到的函数:=IF(COUNTIF(A:A,A2)>1,IF(COUNTIF(A$2:A2,A2)=1,"FIRST",""),"FIRST")
COUNTIF(range, criteria): 计算区域内满足条件的单元格数量。
range: 选中一个范围criteria: 判断条件,可以是一个字符串,返回单元格内等于该字符串的数量。也可以是一个判断,例如>5,则判断range内大于5的单元格数量。
IF(condition, val1, val2): 如果满足条件,则返回 val1 否则返回 val2。
- condition: 判断条件
- val1: 为真的值
- val2: 回退值
所以我们这里的思路就是:对于一个单元格,统计它上面和它自己所有单元格的范围内,值和自己相等的单元格数量。当值为 1 时,就说明该单元格的值是所有重复的值中的第一个,这时我们给他打上一个标记,就可以利用 Excel 的筛选功能就可以做到不删除数据,又能筛选出重复的第一个了。
碰到的坑
由于我们的判断条件是当前单元格和它上面的区域,也就是说如果我们对单元格进行排序或者其它操作,那么我们的标记就会发生变动。如果你只想给重复的第一个值进行一些其它的修改,那么可能一次排序就会毁掉你的所有修改。
这个问题的解决方法也很简单,我们只需要给所有行新建一列,名字叫做序号,值从任意值开始递增,在顺序被我们打乱后,只需要按照序号进行排序就可以恢复到原来的状态。
待补坑
挖个坑在这里,后面碰到了新的需要再来写。
Note
前言
由于我原本是一个搞 Java 的,未来想要转型搞 GoLang。结果在使用的时候发现一个对我这种搞 Java 的非常难以理解的情况:
type Object struct {
data int
}
func updateObj(obj Object) {
obj.data++
}
func main() {
var obj Object
// expect 0
fmt.Println(obj.data)
updateObj(obj)
// expect 1
fmt.Println(obj.data)
}
go
"正常情况"下,这段代码应该依次打印 0 和 1. 但是实际却是:
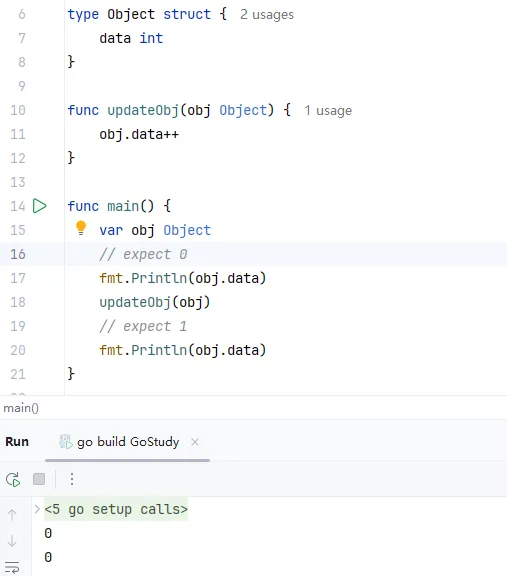 \
\
可以发现输出了两个 0.
可以发现 GoLang 里面参数传递没有和 Java 一样那么无脑。。。很显然,这里直接把对象复制了一遍然后传给了函数,如果大家对 C/C++ 稍微了解过的话,就可以发现这个逻辑是一样的:调用函数是值传递。
什么是引用
这里我直接说结论了,对于一个变量来说,它有两个关键属性:
- 值
- 地址
例如下面的代码:
var obj Object
var objRef = &obj
go
对 obj 来说,它的值为结构体的数据,这里为了方便我们称它为 a, obj 的地址这里假设为 b。那么对于 objRef 来说,它的值就是 b,地址就是内存中的另外一块地址。
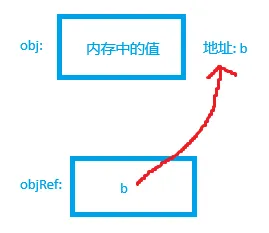
如上图所示,蓝色方框里面代表变量当前的值。
对于 obj 的值具体是什么样的,个人猜测这里应该是一个 8 字节的指针指向结构体内存地址开始的位置(不一定都是全部表示开始位置,可能还会有其它信息),然后底层根据结构体大小信息读取相应范围内的数据,就能够表示一个结构体了。
但是我们在复制这个 值 的时候,不能仅只复制第一个 8 字节,也就是那个指针,也必须要把后面跟着的那一大块全部全部复制。
Important这里只是我为了方便记忆根据个人经验写出来的!没有依据!没有依据!没有依据!
切片是否需要引用
再来看一个例子(Object结构体省略了):
func updateObj(arr []Object) {
arr[0] = Object{data: 1}
}
func main() {
arr := make([]Object, 1)
fmt.Println(arr[0].data)
updateObj(arr)
fmt.Println(arr[0].data)
}
go
输出:
0 1log
可以发现切片使用函数传递后还能够影响原来的值。其实根据切片的结构就可以发现(internal/unsafeheader/unsafeheader.go):
type Slice struct {
Data unsafe.Pointer
Len int
Cap int
}
go
可以发现这个结构体里面还有一个指针指向了真正的数据。这一点让我想起当初刚学 C 语言的时候用 malloc 声明一串连续的内存地址然后用来当数组的时候。。。
所以我们将切片传给函数时,其实也复制了值,但是复制的没这么多,就只有结构体这三个字段,在 64 位系统上也就 24 字节。
所以切片你想用引用就用,但是一般的习惯是不用,因为也浪费不了多少空间,而且后面用的时候解引用也麻烦。
除了切片外 string、map 和 chan 也可以这样使用。
真的不用引用吗
再来看个有意思的例子:
func updateObj(arr []Object) {
arr[0].data++
}
func main() {
arr := make([]Object, 1)
val := Object{data: 0}
arr[0] = val
updateObj(arr)
fmt.Println(val.data)
}
go
输出:
0log
理论上这里应该输出 1,但是却输出了 0,这不是和我们之前得出的结论相违背吗?
不知道你还记不记得我之前说在 C 里面声明一串连续的内存地址,在这里,切片元素的类型是 Object,所以这一串内存中存的就是 Object 具体的值,而不是 val 的内存地址。
如果你将 arr[0].data 打印,可以发现它的值确实自增了。
所以说我们将值添加到切片中时,也会发生值的复制。
方法返回值
那么既然入参会复制值,那么返回值会怎么样呢?
type Object struct {
data int
data2 int
data3 int
}
func createObj() Object {
var obj = Object{data: 2}
fmt.Printf("函数中的内存地址为: %p\n", &obj)
return obj
}
func main() {
r := createObj()
fmt.Printf("函数返回后的内存地址为: %p\n", &r)
fmt.Println(&r)
}
go
输出:
函数中的内存地址为: 0xc0000ae018 函数返回后的内存地址为: 0xc0000ae000go
可以发现两个内存地址相差 18, 转换为十进制,就是 24, 而我们的结构体也正好是 24 字节,说明返回时也发生了复制。
总结
- 能用引用就用引用,不管是返回值还是方法参数,避免对象过多的复制。不需要担心垂悬引用,GoLang 会为方法进行逃逸分析,根据分析结果决定将对象创建在堆中还是在栈上。
- 切片、
map、string和chan可以不用引用直接传递。当然也可以用引用,区别不大。 - 在更新切片、
map等第二点提到的数据结构前,应该将值更新至最新状态后再添加,因为每次添加到这些结构中都会发生一次复制。
Important本文基于 spring-jdbc-6.1.13、mybatis-spring-boot-starter-3.0.3
本文主要是一些总结性的结论,不会大量展示源码,建议自己打断点边跟边看或者后面回顾的时候看。
开头废话
首先来一个非常现实的问题,当 Mybatis 离开了 Spring,你还会用吗?
首先我们来看一下没有 Spring 该怎么用:
DataSource dataSource = BlogDataSourceFactory.getBlogDataSource();
TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment = new Environment("development", transactionFactory, dataSource);
Configuration configuration = new Configuration(environment);
configuration.addMapper(BlogMapper.class);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
try (SqlSession session = sqlSessionFactory.openSession(true)) {
BlogMapper blogMapper = session.getMapper(BlogMapper.class);
blogMapper.doSth();
// ...
}
java
有没有发现这里很违背我们的"常识"?在 Spring 中,我们都是直接注入 Mapper 然后直接就开始用了。而在这里,我们还需要自己开 SqlSession 来获取 Mapper。
接下来,本文将带你详细了解 Spring 是如何管理 Mybatis 资源的。
Mybatis-Spring 原理
在 Mybatis 文档的 作用域(Scope)和生命周期 中提到: 每个线程都应该有它自己的 SqlSession 实例。每次收到 HTTP 请求,就可以打开一个 SqlSession,返回一个响应后,就关闭它。所以 SqlSession 是不能在多线程复用的, 而 Mapper 是由 SqlSession 创建的,也是不能复用的。
那么在 Spring (实际是 Mybatis-Spring)为什么可以直接复用呢?我们先来打个断点看一下我们的 Mapper 类:
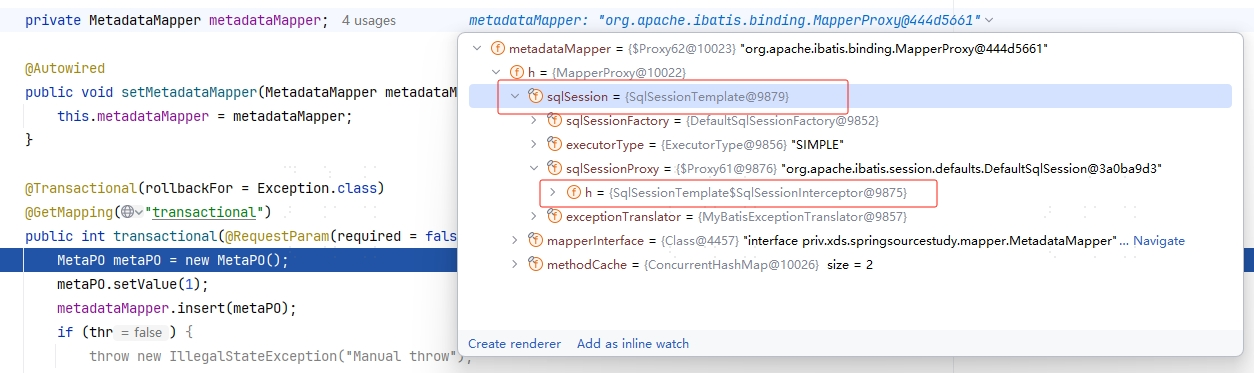
通过上图可以发现,Mapper 中的用的 SqlSession 是 SqlSessionTemplate,而它的内部又代理了另外一个 SqlSession,这里就可以肯定它用了 代理模式,我们来看一下它的代理是怎么处理的:
private class SqlSessionInterceptor implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 获取 sqlSession
SqlSession sqlSession = getSqlSession(SqlSessionTemplate.this.sqlSessionFactory,
SqlSessionTemplate.this.executorType, SqlSessionTemplate.this.exceptionTranslator);
try {
// 调用**真正的** SqlSession 的方法
Object result = method.invoke(sqlSession, args);
// 判断是否开启了事务
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// force commit even on non-dirty sessions because some databases require
// a commit/rollback before calling close()
// 没开,就直接提交
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (SqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
// release the connection to avoid a deadlock if the translator is no loaded. See issue #22
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
sqlSession = null;
Throwable translated = SqlSessionTemplate.this.exceptionTranslator
.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
// 关闭
if (sqlSession != null) {
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}
}
java
这里方法第一行 getSqlSession,这里就不进去看了,这个方法的作用是创建一个真正的 SqlSession,并且如果开启了事务,就把这个 SqlSession 绑定到线程变量里面。
好!这里就很清楚了:我 Mapper 用的 SqlSession 是一个假的(代理类) SqlSession,里面没有任何真正的数据库连接,当你真的去执行数据库操作需要创建连接的时候,我就给你创建一个。你要是开了事务,我还会给你把连接绑定到线程变量里面,你要是下次又要获取连接,我就直接从线程变量里面拿;要是没开事务,用完我就给你自动提交并且关了。
那么绑到线程变量里面的事务又由谁来关闭呢?这里最合适的做法就是:事务在哪里开启,你就在哪里关闭。
什么意思?例如我们一般就是在服务类中调用 Mapper,当方法上加上 @Transactional 注解就可以开启事务了。OK! 你要是用了这个注解,我就在执行方法前,也往线程变量里面写一个标识,表示我开启了一个事务。后面在假的 SqlSession 里面,我去查这个线程变量标识来判断你开了事务没有。同理,我在这里可以往线程变量里面绑,我也可以在方法结束后获取创建的连接,然后直接在这里关闭。
总结一下就是:
- 用动态代理增强入口类(一般是服务类),如果方法有
@Transactional, 就往线程变量里面写一个标识,这里我们叫T。写完标识后,正常调用入口方法。 - 当入口类中的方法调用
Mapper里面的方法时,里面的假SqlSession会判断线程变量有没有标识T,如果有,返回之前在线程变量中缓存的、真正的SqlSession,这里我们叫S,如果S中没有数据,就创建一个新的连接并且保存到S中。如果没有标识T,即没有开启事务,就创建一个新的数据库连接,并且在用完后关闭。 - 当入口类中的方法返回后,检查线程变量
S是否有值,如果有,就将其提交并关闭。
现在你已经知道 Mybatis-Spring 的基础原理了,现在你可以:
- 手搓一个简单的实现:[手搓一个简单的 Mybatis-Spring](#手搓一个简单的 Mybatis-Spring)
- 自己去研究源码
- 继续看这篇文章后面枯燥的部分
如果你选择自己看源码,这里给你两个入口:
- 第一个就是上面提到的
SqlSessionTemplate - 第二个就是
org.springframework.transaction.interceptor.TransactionAspectSupport,这个类就是我们前面提到的"入口类"的动态代理。
Important再次声明,源码强烈推荐自己打断点看,本文后面的东西大部分只提供总结性的内容!。 到目前为止,我真的很少见到有人能把枯燥的源码详解写的很有意思的,因为这种很难避免贴上大部分源码上去,所以我强烈推荐自己打断点, 然后写下自己的总结方便未来复习!所以我这篇文章后半部分就全是我的总结。
没错,我是个标题党,标题写了 详解 就是为了把你骗进来...
在继续看前,需要了解一个非常重要的类:TransactionSynchronizationManager:
public abstract class TransactionSynchronizationManager {
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations =
new NamedThreadLocal<>("Transaction synchronizations");
private static final ThreadLocal<String> currentTransactionName =
new NamedThreadLocal<>("Current transaction name");
private static final ThreadLocal<Boolean> currentTransactionReadOnly =
new NamedThreadLocal<>("Current transaction read-only status");
private static final ThreadLocal<Integer> currentTransactionIsolationLevel =
new NamedThreadLocal<>("Current transaction isolation level");
private static final ThreadLocal<Boolean> actualTransactionActive =
new NamedThreadLocal<>("Actual transaction active");
// snip
}
java
这个类就是用于管理我们线程变量的绑定的:
resources: 保存当前线程的数据库连接,便于后续事务获取synchronizations: 保存事务同步的回调,例如beforeCommit、afterCompletion等currentTransactionName:保存事务的名称currentTransactionReadOnly:标识当前事务是否只读currentTransactionIsolationLevel: 当前事务隔离级别actualTransactionActive: 当前线程是否真的开启了事务
例如调用 org.springframework.transaction.support.TransactionSynchronizationManager#isActualTransactionActive 就可以判断当前线程是否开启了事务。
SqlSession 的懒创建与 ThreadLocal 的绑定
在第一次尝试获取 SqlSession 时,就会尝试绑定相关的 ThreadLocal。
org.mybatis.spring.SqlSessionTemplate.SqlSessionInterceptor#invoke -> org.mybatis.spring.SqlSessionUtils#getSqlSession -> org.mybatis.spring.SqlSessionUtils#registerSessionHolder(部分无关紧要的代码被省略):
private static void registerSessionHolder(SqlSessionFactory sessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator, SqlSession session) {
SqlSessionHolder holder;
// 判断是否需要开启事务.
if (TransactionSynchronizationManager.isSynchronizationActive()) {
Environment environment = sessionFactory.getConfiguration().getEnvironment();
if (environment.getTransactionFactory() instanceof SpringManagedTransactionFactory) {
LOGGER.debug(() -> "Registering transaction synchronization for SqlSession [" + session + "]");
holder = new SqlSessionHolder(session, executorType, exceptionTranslator);
// 绑定 resources 到 ThreadLocal
TransactionSynchronizationManager.bindResource(sessionFactory, holder);
// 绑定 synchronizations
TransactionSynchronizationManager
.registerSynchronization(new SqlSessionSynchronization(holder, sessionFactory));
// 标识当前事务已经绑定了 synchronizations
holder.setSynchronizedWithTransaction(true);
// 引用计数加一
holder.requested();
} else {
// 判断当前是不是使用 SpringManagedTransactionFactory 来管理事务,如果不是则直接报错
}
} else {
// 啥都不做
}
}
java
至此,事务就成功开启了。后面的 Mapper 想要获取 SqlSession 就可以直接复用了:
// org.mybatis.spring.SqlSessionUtils#getSqlSession
public static SqlSession getSqlSession(SqlSessionFactory sessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
notNull(sessionFactory, NO_SQL_SESSION_FACTORY_SPECIFIED);
notNull(executorType, NO_EXECUTOR_TYPE_SPECIFIED);
// 获取绑定的资源
SqlSessionHolder holder = (SqlSessionHolder) TransactionSynchronizationManager.getResource(sessionFactory);
// 获取对应的 SqlSession,并将引用计数加一
SqlSession session = sessionHolder(executorType, holder);
if (session != null) {
return session;
}
// 线程还没有绑定,创建新的并判断是否需要绑定,也就是我们上面看到的代码
LOGGER.debug(() -> "Creating a new SqlSession");
session = sessionFactory.openSession(executorType);
registerSessionHolder(sessionFactory, executorType, exceptionTranslator, session);
return session;
}
java
SqlSession 的释放
在自动提交的情况下,SqlSession 用完就会被释放,在 org.mybatis.spring.SqlSessionTemplate.SqlSessionInterceptor#invoke 中的 finally 代码块就可以看到,最后调用了 org.mybatis.spring.SqlSessionUtils#closeSqlSession 来释放 SqlSession:
public static void closeSqlSession(SqlSession session, SqlSessionFactory sessionFactory) {
notNull(session, NO_SQL_SESSION_SPECIFIED);
notNull(sessionFactory, NO_SQL_SESSION_FACTORY_SPECIFIED);
SqlSessionHolder holder = (SqlSessionHolder) TransactionSynchronizationManager.getResource(sessionFactory);
if ((holder != null) && (holder.getSqlSession() == session)) {
LOGGER.debug(() -> "Releasing transactional SqlSession [" + session + "]");
// 引用计数减一
holder.released();
} else {
LOGGER.debug(() -> "Closing non transactional SqlSession [" + session + "]");
// 自动提交,直接关闭
session.close();
}
}
java
可以发现在开启事务的情况下,这里仅仅是将引用计数减一,那么真正的关闭在哪呢?
其实也不难猜到,我们在哪个方法上的 @Transactional,这个方法结束后肯定就会去关闭 SqlSession。这里是通过动态代理实现的,具体的类为:org.springframework.transaction.interceptor.TransactionAspectSupport,直接从 invokeWithinTransaction 开始看就可以了。
可以在里面找到 commitTransactionAfterReturning 这个方法,很显然,这个方法就是用来提交并关闭连接的:
protected void commitTransactionAfterReturning(@Nullable TransactionInfo txInfo) {
if (txInfo != null && txInfo.getTransactionStatus() != null) {
if (logger.isTraceEnabled()) {
logger.trace("Completing transaction for [" + txInfo.getJoinpointIdentification() + "]");
}
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
}
java
可以发现,如果没有开启事务,则不会做任何事。否则将会获取 TransactionManager 然后调用 commit 方法。
点进去继续追 org.springframework.transaction.support.AbstractPlatformTransactionManager#commit -> org.springframework.transaction.support.AbstractPlatformTransactionManager#processCommit(这里方法很长,只保留部分代码):
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
boolean commitListenerInvoked = false;
try {
boolean unexpectedRollback = false;
prepareForCommit(status);
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
beforeCompletionInvoked = true;
if (status.hasSavepoint()) {
// snip
}
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction commit");
}
unexpectedRollback = status.isGlobalRollbackOnly();
this.transactionExecutionListeners.forEach(listener -> listener.beforeCommit(status));
commitListenerInvoked = true;
doCommit(status);
}
else if (isFailEarlyOnGlobalRollbackOnly()) {
unexpectedRollback = status.isGlobalRollbackOnly();
}
// Throw UnexpectedRollbackException if we have a global rollback-only
// marker but still didn't get a corresponding exception from commit.
if (unexpectedRollback) {
throw new UnexpectedRollbackException(
"Transaction silently rolled back because it has been marked as rollback-only");
}
}
catch (UnexpectedRollbackException ex) {
// snip
}
catch (TransactionException ex) {
// snip
}
catch (RuntimeException | Error ex) {
// snip
}
// Trigger afterCommit callbacks, with an exception thrown there
// propagated to callers but the transaction still considered as committed.
try {
triggerAfterCommit(status);
}
finally {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_COMMITTED);
if (commitListenerInvoked) {
this.transactionExecutionListeners.forEach(listener -> listener.afterCommit(status, null));
}
}
}
finally {
cleanupAfterCompletion(status);
}
}
java
正常情况下(没有异常、事务正常提交),主要是这样的流程(TransactionManager 的实现类默认是 JdbcTransactionManager):
prepareForCommit: 在提交前进行一些准备工作。triggerBeforeCommit: 调用同步器(TransactionSynchronization)的beforeCommit方法triggerBeforeCompletion: 调用同步器(TransactionSynchronization)的beforeCompletion方法doCommit: 获取到Connection并提交triggerAfterCommit: 调用同步器(TransactionSynchronization)的afterCommit方法triggerAfterCompletion: 调用同步器(TransactionSynchronization)的afterCompletion方法cleanupAfterCompletion: 清除绑定的ThreadLocal,恢复Connection的状态等(设置自动提交、隔离级别等),如果有被挂起的事务,则恢复对应的事务。
事务提交了两次?
在之前我们可以看到,默认的同步器是 SqlSessionSynchronization。而在 org.mybatis.spring.SqlSessionUtils.SqlSessionSynchronization#beforeCommit 中我们可以发现,这里又调用了 SqlSession 的 commit 方法,所以这个事务一共提交了两次 !?
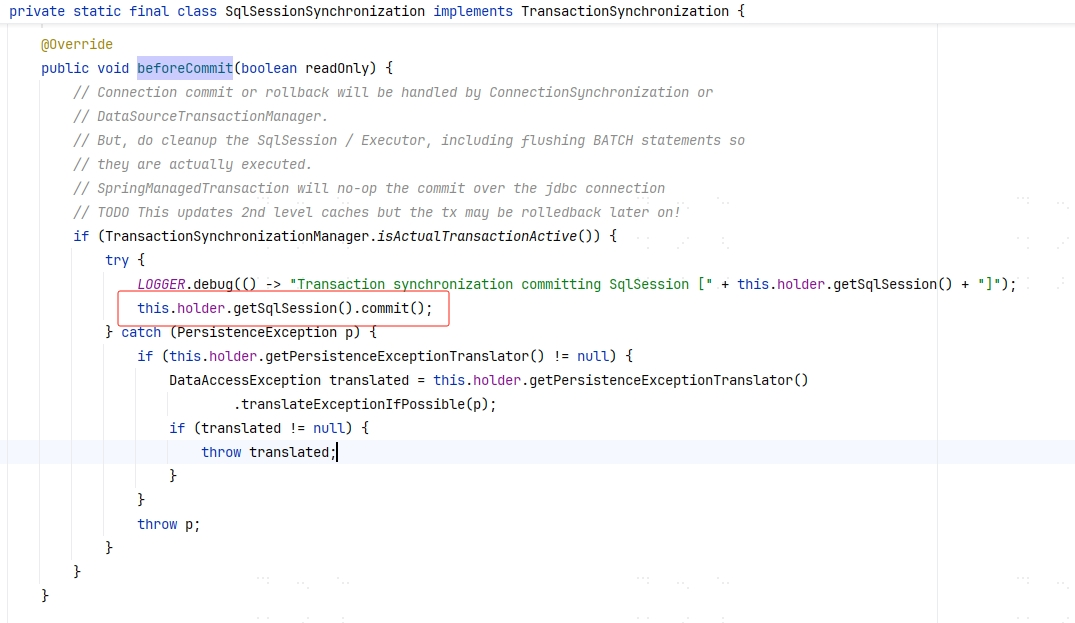
没错,第一次看到这里我确实被迷惑住了。但是其实上面的注释已经说的很清楚了,吃了不懂英语的坑😢。
这段大致意思如下:
Connection的 提交 或者 回滚 将会被ConnectionSynchronization或DataSourceTransactionManager处理。但是,请清理
SqlSession/Executor,包括 批处理 操作,以确保它们实际被执行过。
SpringManagedTransaction不会真的在 jdbc 连接的层面上 提交 。
还是不太诗人话,简单来说就是你在同步器里只需要确保刷新 SqlSession、 Executor 和批处理操作就行了,提交的事情不用你管。
那么实际是怎么样的呢,在继续前我们需要再回到没有 Spring 的 mybatis。
TransactionFactory
还记得前面我们不使用 Spring 来配置 mybatis 的时候吗?我们需要手动配置一个 TransactionFactory,在文档中直接使用了 JdbcTransactionFactory,我们来看看它的实现。
既然是工厂类,就只需要关注它返回的类型了,这里它返回的是 JdbcTransaction,我们接着看。
这里主要关注它的 commit 方法:
@Override
public void commit() throws SQLException {
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Committing JDBC Connection [" + connection + "]");
}
connection.commit();
}
}
java
可以发现它的 commit 方法是真的直接调用 jdbc 连接提交了。还记得我们之前翻译的吗,在 Spring 里面:SpringManagedTransaction不会真的在 jdbc 连接的层面上 *提交* 。 我们来看 Spring 实现里的commit`:
@Override
public void commit() throws SQLException {
if (this.connection != null && !this.isConnectionTransactional && !this.autoCommit) {
LOGGER.debug(() -> "Committing JDBC Connection [" + this.connection + "]");
this.connection.commit();
}
}
java
可以发现它加了一个最关键的判断:!this.isConnectionTransactional。那么可以说明,如果当前开启了事务,那么调用 SqlSession#commit 就不会真正的提交。
Note这里省略了部分上下文。
SqlSession#commit会调用Executor#commit(org.apache.ibatis.executor.BaseExecutor#commit),最终会调用org.apache.ibatis.transaction.Transaction#commit
所以在这里调用 SqlSession 的 commit,只是为了清除缓存而已,并没有真正提交的意思。
事务的创建
在 Spring 中可以设置事务的传播级别(TransactionDefinition):
PROPAGATION_REQUIRED(默认): 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。PROPAGATION_NESTED:创建一个子事务,如果子事务回滚,对应的父事务也会回滚(如果有)。PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
那么事务在创建时,是如何根据不同的传播级别来创建事务的呢?
在 org.springframework.transaction.interceptor.TransactionAspectSupport#createTransactionIfNecessary -> org.springframework.transaction.support.AbstractPlatformTransactionManager#getTransaction 就可以找到相关开启事务的代码。
这里代码很长,但不管怎么样,最终都是返回一个 TransactionStatus,默认的实现是 org.springframework.transaction.support.DefaultTransactionStatus:
public class DefaultTransactionStatus extends AbstractTransactionStatus {
@Nullable
private final String transactionName;
@Nullable
private final Object transaction;
private final boolean newTransaction;
private final boolean newSynchronization;
private final boolean nested;
private final boolean readOnly;
private final boolean debug;
@Nullable
private final Object suspendedResources;
// snip
}
java
这些字段的意思分别是:
transactionName: 事务的名称,一般是被代理的方法全限定名称,例如foo.bar.TestService.doService。transaction: 保存了org.springframework.transaction.support.AbstractPlatformTransactionManager#doGetTransaction的返回值,默认类型为org.springframework.jdbc.datasource.DataSourceTransactionManager.DataSourceTransactionObject。newTransaction: 是不是一个新的事务。例如多个Transactional方法嵌套,第一个开启事务的方法该值为true,其它的均为false。newSynchronization: 当前事务是否创建了一个新的事务同步器。nested: 是否嵌套(子事务)。readOnly: 是否只读。debug: 用于 debug。suspendedResources: 被挂起的资源,例如在PROPAGATION_REQUIRES_NEW的传播级别下,会创建一个新的事务,旧的事务将会在这里被挂起。
transactionSynchronization
关于 newSynchronization 这个属性,一开始可能还挺懵逼的。如果不想管太多,只需要记住该值为 true 时,后面的事务获取 SqlSession 时才会创建相关同步器。
Note当该值为
true时org.springframework.transaction.support.AbstractPlatformTransactionManager#prepareSynchronization将会绑定相关线程变量,后面线程在获取SqlSession时,org.mybatis.spring.SqlSessionUtils#registerSessionHolder会判断当前是否激活同步器,然后再去绑定相关资源。
那么这个值具体有什么用呢?这里就不得不再回到我们前面的传播级别了。例如 PROPAGATION_NOT_SUPPORTED 级别,它会挂起已有的事务,并且以非事务的状态继续执行,所以这里很明显就不需要绑定同步器。
newSynchronization 的值由 org.springframework.transaction.support.AbstractPlatformTransactionManager#transactionSynchronization 的值决定,而这个值默认为 SYNCHRONIZATION_ALWAYS。也就是永远都会创建同步器,即使没有开启事务。
一共有三个可用的值:
SYNCHRONIZATION_ALWAYS(默认): 永远创建同步器,即使没有事务。SYNCHRONIZATION_ON_ACTUAL_TRANSACTION:仅在有事务的情况下创建。SYNCHRONIZATION_NEVER:永远不创建。
事务的挂起和恢复
在 Spring 是可以嵌套事务的,例如我们使用 REQUIRES_NEW 的传播级别,就能够在已有事务的前提下开启一个完全隔离的新事务。那么旧的事务在这里会怎么处理呢?
眼见的大伙已经可以看到了,在 org.springframework.transaction.support.AbstractPlatformTransactionManager#getTransaction 中,有一个判断是否已经存在事务的代码:
@Override
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException {
// snip
if (isExistingTransaction(transaction)) {
// Existing transaction found -> check propagation behavior to find out how to behave.
return handleExistingTransaction(def, transaction, debugEnabled);
}
// snip
}
java
具体的代码就不细看了,大致流程如下:
- 调用同步器的
suspend方法(org.springframework.transaction.support.AbstractPlatformTransactionManager#suspend)。 - 清除旧事务绑定的相关线程变量(
org.springframework.transaction.support.AbstractPlatformTransactionManager#suspend)。 - 将旧事务保存(
SuspendedResourcesHolder),开启新的事务,并将新事务status#suspendedResources设置为旧的Holder。
事务恢复的代码在 org.springframework.transaction.support.AbstractPlatformTransactionManager#cleanupAfterCompletion 里面的最后一段,它会调用 resume 方法来恢复事务:
protected final void resume(@Nullable Object transaction, @Nullable SuspendedResourcesHolder resourcesHolder)
throws TransactionException {
if (resourcesHolder != null) {
Object suspendedResources = resourcesHolder.suspendedResources;
if (suspendedResources != null) {
doResume(transaction, suspendedResources);
}
List<TransactionSynchronization> suspendedSynchronizations = resourcesHolder.suspendedSynchronizations;
if (suspendedSynchronizations != null) {
TransactionSynchronizationManager.setActualTransactionActive(resourcesHolder.wasActive);
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(resourcesHolder.isolationLevel);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(resourcesHolder.readOnly);
TransactionSynchronizationManager.setCurrentTransactionName(resourcesHolder.name);
doResumeSynchronization(suspendedSynchronizations);
}
}
}
java
代码很简单,其实就是调用同步器的 resume, 然后再重新绑定相关的线程变量。
手动开启事务
下面就直接贴代码了:
@Component
class Test {
@Autowired
private PlatformTransactionManager txManager;
public void test() {
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
TransactionStatus status = txManager.getTransaction(def);
try {
// ...
txManager.commit(status);
} catch (Exception e) {
txManager.rollback(status);
}
}
}
java
非 Spring 环境指定 Mapper 位置
在非 Spring 环境中用 mybatis 一定会碰到这个问题:怎么修改 Mapper 的路径?
在 Spring 中可以通过下面的配置实现:
mybatis:
mapper-locations: classpath:mapper/*.xml
yaml
但是很遗憾,Mybatis 本身是没有提供任何配置项来修改 xml 存放位置的。也就是说默认情况下,你只能把 XML 和 接口 放到一个文件夹里面。
这里我们来看一下 Spring 是怎么做到自定义 mapper 位置的(org.mybatis.spring.SqlSessionFactoryBean#buildSqlSessionFactory):
Configuration targetConfiguration;
// ...
for (Resource mapperLocation : this.mapperLocations) {
// ...
XMLMapperBuilder xmlMapperBuilder = new XMLMapperBuilder(mapperLocation.getInputStream(),
targetConfiguration, mapperLocation.toString(), targetConfiguration.getSqlFragments());
xmlMapperBuilder.parse();
}
java
这里只需要获取到 xml 的输入流,就可以自定义解析 Mapper了。
手搓一个简单的 Mybatis-Spring
由于我之前想开发一个 IDEA 插件,需要用到 sqlite, 所以上了 Mybatis 并且顺便照着 Mybatis-Spring 封装了一遍。虽然插件我已经弃坑了,但是这份代码封装的还是没有问题的。
最终封装的效果是:支持声明式主键,但是不支持传播级别等其它高级特性。
直接看代码(kotlin 写的,但没有用很高级的特性,不会的话也能看懂):Github
推荐从下面的类开始看:
- SqlSessionTemplate: 初始化和缓存 SqlSession。
- ServiceEnhanceInvocationHandler: 增强服务类,负责事务的开启和结束。
安装
Ansible 不支持在 windows 上作为控制节点使用,虽然可以安装,但是运行不了: Why no Ansible controller for Windows?。
但是 windows 可以作为被控制的节点来使用。
创建虚拟环境并安装:
python3 -m venv ansible source ansible/bin/activate python3 -m pip install ansible-coreshell
如果是 python3.6 最高只能装 2.11 更高的版本需要升级 python 版本。
基础概念
ansible 中有下面几种常用的特殊名词:
- Inventory: "物品栏"(不知道该怎么翻译...),包含了一组或多组远程服务器
- Play: 剧本,可以理解为一个完整的工作流程,一般由多个
Task组成。其中每个Play都会指定Inventory中的一组服务器。 - Task: 任务,通常同来定义一个操作.
- Role: 与
Play类似,但是在声明时不需要指定Inventory,所以一般不会直接写Play,而是直接使用Role来编写,方便多次复用。
可以这样理解: 一个 Play 代表已经编辑好的一部电影。通过指定好角色(Inventory)和剧情(Task),构成一部电影(Play)。
所以通常一个 Play 文件包含了 Inventory 和 Task。由于 Inventory 在这里直接写死了,一般会直接使用 Role 来代替 Play,在实际运行的时候指定对应的 Inventory。
创建 Inventory
创建一个 Inventory(inventory.ini):
[myhosts] 192.0.2.50 192.0.2.51 192.0.2.52ini
测试连接:
# verify
ansible-inventory -i inventory.ini --list
# ping
ansible myhosts -m ping -i inventory.ini
bash
使用 ansible
一个常用的目录结构如下:
. ├── env ├── inventory └── project └── roles └── my_role ├── handlers ├── tasks ├── templates └── varstext
自定义 filter
想要创建一个 filter,首先在任意目录中创建一个 python 文件:
def greet(name):
return f"Hello, {name}!"
class FilterModule(object):
def filters(self):
return {
'greet': greet,
}
python
上面的代码就实现了一个 filter,然后使用环境变量来指向对应的目录:
export ANSIBLE_FILTER_PLUGINS=/path/to/custom/filter_plugins
bash
使用:
# playbook.yml
---
- hosts: localhost
tasks:
- name: Use global custom greet filter
debug:
msg: "{{ 'World' | greet }}"
yaml
输出:
TASK [Use global custom greet filter] ********************************* ok: [localhost] => { "msg": "Hello, World!" }text
注意,这么调用是错误的:
- name: Debug debug: msg: "{{ greet('World') }}"text
必须使用前一种类似管道符的语法。
传递多个参数
上面的代码中,我们使用 filter 传递了一个参数进去,然后返回一个值。但是如果要传递多个参数该怎么办?
解决方法如下:
# filter_plugins/custom_filters.py
def greet(name, greeting="Hello"):
return f"{greeting}, {name}!"
class FilterModule(object):
def filters(self):
return {
'greet': greet,
}
python
使用:
# playbook.yml
- hosts: localhost
tasks:
- name: Use custom greet filter with multiple arguments
debug:
msg: "{{ 'World' | greet('Good morning') }}"
yaml
巨奇怪有木有...
加载外部参数
在前面我们说过可以通过 ansible-runner 来提前获取好参数来提供给 ansible 使用,但是 ansible 自己也可以主动通过调用 Python 脚本来动态获取外部参数。
和 filter 插件一样,创建一个 Python 文件:
# lookup_plugins/my_custom_lookup.py
from ansible.plugins.lookup import LookupBase
class LookupModule(LookupBase):
def run(self, terms, variables=None, **kwargs):
# Custom logic here
return [f"Hello, {terms[0]}!"]
python
然后使用环境变量指向这个目录:
export ANSIBLE_LOOKUP_PLUGINS=/path/to/custom/filter_plugins
bash
使用:
# playbook.yml
- hosts: localhost
tasks:
- name: Use custom lookup plugin
debug:
msg: "{{ lookup('my_custom_lookup', 'World') }}"
yaml
输出:
TASK [Use custom lookup plugin] ************************************* ok: [localhost] => { "msg": "Hello, World!" }text
每个参数的意思
这里文档非常🌿🥚,完全没讲每个参数是什么意思,这里就详细记一下,防止以后忘了。
terms 参数
terms 代表在使用 lookup 时后面的列表参数。
使用时这样传:
# In a playbook or template
{{ lookup('my_custom_lookup', 'argument1', 'argument2') }}
yaml
terms 就是 ['argument1', 'argument2']。
variables 参数
这个很好理解,就是可以获取到上下文中的参数:
# In the lookup plugin
def run(self, terms, variables=None, **kwargs):
# 获取上下文中的 my_var 参数
value_from_var = variables.get('my_var')
return [f"{value_from_var}, {terms[0]}"]
python
kwargs 参数
这个可以理解为具名参数,类型是一个字典:
# In a playbook or template
{{ lookup('my_custom_lookup', 'term', option1='value1', option2='value2') }}
yaml
对于 option1 和 option2 就可以直接在 kwargs 通过字典的方式获取到。
动态加载模板文件并转移
例如在上面一个 role 的目录中,我们有一个 templates 模板,一般这个文件夹里面放的都是配置文件,如果我们想要一口气全部发送到远程服务器里面, 除了可以一个一个写,还可以这样写:
- name: Transfer Template
with_fileglob:
- "templates/*.j2"
ansible.builtin.template:
src: "{{ item }}"
dest: "/dest/{{ item | template_glob_path_to_dest }}"
yaml
这里需要声明一个 filter 来去掉多余的路径:
def template_glob_path_to_dest(string: str):
target = 'templates/'
pos = string.rfind(target)
if pos == -1:
raise RuntimeError('Could not find template relative path')
return string[pos + len(target):-3]
class FilterModule(object):
def filters(self):
return {
'template_glob_path_to_dest': template_glob_path_to_dest
}
python
注入参数
在 task 中注入参数
在 task 中注入参数需要使用 set_fact,而不是 vars:
- name: My play
hosts: localhost
tasks:
- name: Ping my hosts
set_fact:
who: world
- name: Print message
debug:
msg: "hello {{ who }}"
yaml
对于 vars 声明的参数,仅在当前任务中有效。
组合多个 role
一般在多个 role 中,可能会出现通用的逻辑,例如多个 Tomcat 应用,每个应用都需要单独的 Tomcat 目录,如果每个服务都写一遍会导致十分臃肿,所以我们完全可以将通用的 role 抽离出来,供其它的 role 使用。
假设我们已经有了一个安装 Tomcat 的 role:roles/common/tasks/main.yaml, 详细代码见 安装 tomcat。
假设我们有服务 A 和 B 都需要安装 Tomcat,分别编辑 roles/A/meta/main.yaml 和 roles/B/meta/main.yaml:
dependencies:
- { role: common, service_root: "{{ Values.metadata.rootPath }}/xxx" }
yaml
上面的内容两个应用需要指定不同的 service_root 参数,否则对应的 role 只会执行一遍。
common具体的代码可以看下面的 安装 tomcat
例子
安装 tomcat
这个例子会在本地缓存一份 tomcat 包,只要文件名称满足 apache-tomcat-*.tar.gz 就可以被自动获取,并安装到远程服务器。
如果本地不存在任何包时,将会自动从远程服务器中下载。
需要提供下面两个参数:
ansible_cache_directory: 存放 tomcat 包的位置service_root: 远程服务器的应用根路径
创建文件 roles/common/tasks/main.yaml:
- name: Check Tomcat Exist
stat:
path: "{{ service_root }}/tomcat"
register: tomcat
- name: Init Tomcat
when: not tomcat.stat.exists
import_tasks: install.yaml
- name: Fail if tomcat occupied
when:
- tomcat.stat.exists
- not tomcat.stat.isdir
fail:
msg: "Tomcat directory '{{ tomcat_directory }}' exist, but it's a file!"
yaml
具体的安装逻辑(roles/common/tasks/install.yaml):
- name: Search local Tomcat
vars:
search_path: "{{ ansible_cache_directory }}/apache-tomcat-*.tar.gz"
set_fact:
tomcat_files: "{{ lookup('ansible.builtin.fileglob', search_path, wantlist = True ) }}"
- name: Download tomcat
delegate_to: localhost
when: tomcat_files.__len__() == 0
block:
- shell:
cmd: "mkdir -p {{ ansible_cache_directory }}"
- vars:
dest: "{{ ansible_cache_directory }}/apache-tomcat-10.1.28.tar.gz"
get_url:
url: 'https://mirrors.huaweicloud.com/apache/tomcat/tomcat-10/v10.1.28/bin/apache-tomcat-10.1.28.tar.gz'
checksum: sha512:b3177fb594e909364abc8074338de24f0441514ee81fa13bcc0b23126a5e3980cc5a6a96aab3b49798ba58d42087bf2c5db7cee3e494cc6653a6c70d872117e5
dest: "{{ dest }}"
- vars:
dest: "{{ ansible_cache_directory }}/apache-tomcat-10.1.28.tar.gz"
set_fact:
tomcat_files: "{{ [dest] }}"
rescue:
- name: Tip how to fix
fail:
msg: 'Failed to download Tomcat. You need to download Tomcat manually and then place it in `{{ ansible_cache_directory }}`. Please ensure that the file name follows the pattern `apache-tomcat-*.tar.gz`.'
- name: Fail if multi package
fail:
msg: 'Multiply Tomcat packages found: {{ tomcat_files }}. Either rename it to not follow the pattern `apache-tomcat-*.tar.gz` or keep only one file there.'
when: tomcat_files.__len__() > 1
- name: Send and unzip file.
unarchive:
src: "{{ tomcat_files[0] }}"
dest: "{{ service_root }}"
- name: Adjust folder name
vars:
zip_name: "{{ tomcat_files[0] | to_file_name }}"
shell:
cmd: >
cd {{ service_root }} &&
rm -f {{ service_root }}/{{ zip_name }} &&
mv {{ zip_name[:-7] }} tomcat
yaml
install.yaml 每一步具体的功能如下:
-
Search local Tomcat:使用ansible.builtin.fileglob模块搜索管理节点的缓存目录中的 tomcat 文件,注意需要提供wantlist = True参数,否则返回的将会是一个用逗号分割的字符串,而不是数据。 -
Download tomcat:首先使用when判断上一步中搜素到的 tomcat 文件列表是否为空,如果为空,则从远程下载。这里使用block将具体的下载任务组合为一个整体,任意一个步骤发生错误都会触发rescue中的代码。同时这里使用了delegate_to: localhost来将这个任务交给管理节点处理,而不是远程节点。2.1. 这是一个脚本,确保远程服务器的目录存在
2.2. 从远程下载 tomcat
2.3. 覆盖
tomcat_files变量,以便后续运行 -
Fail if multi package: 判断 tomcat 文件是否有多个,如果有,发出提示并报错返回。 -
Send and unzip file:将 tomcat 发送到远程服务器并解压 -
Adjust folder name:删除多余的压缩包并且重命名 tomcat 目录以便于后续升级
这里还用到了一个 filter:to_file_name。代码如下:
import os
def to_file_name(path: str) -> str:
return os.path.basename(path)
class FilterModule(object):
def filters(self):
return {
'to_file_name': to_file_name,
}
python
自定义模块创建文件夹
在这里自定义一个模块,用于递归创建文件夹,如果文件夹已经存在,返回 Unchanged 状态。
这里实际 ansible 已经提供了响应的模块:
# recursion_mkdir.py
import os.path
from ansible.module_utils.basic import AnsibleModule
def run_module():
module_args = dict(
path=dict(type='list', required=True)
)
result = dict(
changed=False
)
module = AnsibleModule(
argument_spec=module_args,
supports_check_mode=True
)
paths = module.params['path']
if isinstance(paths, str):
paths = [paths]
for path in paths:
if not os.path.isdir(path):
os.makedirs(path, exist_ok=True)
result['changed'] = True
module.exit_json(**result)
def main():
run_module()
if __name__ == '__main__':
main()
python
上面的代码中,虽然指定了 path 的类型为 list,但实际上是可以直接传一个字符串进来的,所以在代码中要做兼容。
之后使用环境变量指定模块目录:
ANSIBLE_LIBRARY=/your/module/directory/bash
使用模块:
- name: Create required directory
recursion_mkdir:
path:
- "/opt/app/home"
- "/opt/app/configuration"
yaml
碰见的坑
使用 shell 启动后台服务立即退出
起因是我打算使用 shell 模块来启动 tomcat 服务:
- name: 'Restart Tomcat'
shell:
chdir: "{{ service_root }}/{{ tomcat_directory_name }}/bin"
cmd: sh startup.sh
yaml
结构执行后,ansible 没保存,tomcat 这里没有运行,也没有日志...
最后查了一下,这里是需要用 nohup 直接在外面启动服务:
- name: 'Restart Tomcat'
shell:
chdir: "{{ service_root }}/{{ tomcat_directory_name }}/bin"
cmd: nohup sh startup.sh 2>&1 > last-boot-log.log &
yaml
使用 ansible-runner
ansible-runner 可以帮助我们通过 Python 代码来调用 ansible 的 API,当需要从外部传入非常多的参数时可以考虑使用这个库。
安装依赖:
# python latest
python3 -m pip install ansible-runner
# python 3.6
python3 -m pip install ansible-runner==2.2.2
shell
运行一个 role:
import ansible_runner
ansible_runner.interface.run(
inventory=inventory_str,
private_data_dir='./',
playbook=play_yaml,
extravars={
'USERNAME': data.username,
'PASSWORD': data.password,
'HOST': data.host
}
)
python
所有的参数需要自己点开 run 方法看里面的注释。
详见:Introduction to Ansible Runner
在上面,我们有一个 private_data_dir,只需要将其指向目录结构的根目录,就可以不输入目录,直接使用文件名称就可以读取到相关的文件了。